Designing Redundant Server Infrastructure: High-Availability Best Practices
-

- March 04th, 2026
- 420 views

Get a free topical map and start building content authority today.
Detected intent: Informational
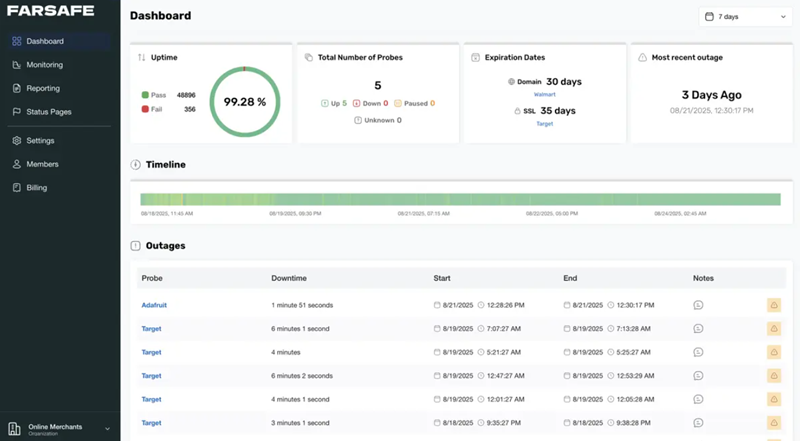
The goal of a resilient IT environment starts with a clear plan for redundant server infrastructure. This guide explains practical architectures, operational controls, and verification steps to keep applications available during hardware failures, software bugs, or site outages.
Key strategies: separate hardware failure domains, use active-active or active-passive failover, replicate state across nodes, automate health checks and recovery, and test recovery regularly. Includes a named 4R framework, a checklist, a real-world example, and practical tips.
redundant server infrastructure: core principles
Redundancy reduces single points of failure by duplicating critical components. Typical approaches combine multiple layers: compute (multiple servers), storage (replication or distributed storage), network (redundant paths and switches), and site-level redundancy (multiple availability zones or data centers). Terms and patterns to know include failover, high availability (HA), load balancing, clustering, replication, and graceful degradation.
Architectures and patterns for high availability
Active-active vs active-passive
Active-active configurations distribute traffic across multiple nodes simultaneously and provide capacity even during maintenance. Active-passive keeps standby capacity ready to take over after a failure. Active-active improves resource utilization and reduces failover time at the cost of more complex synchronization and potential split-brain scenarios.
Network and storage considerations
Design redundant network paths, use link aggregation where appropriate, and separate management traffic from data traffic. For storage, choose synchronous replication for low RPOs and asynchronous replication for long-distance tolerance. Consider distributed filesystems or object stores for stateful services where possible.
Server redundancy best practices checklist
Use this checklist during design and review phases. This is a named checklist: the 4R Redundancy Framework (Redundancy, Replication, Recovery, Review).
- Redundancy: Separate failure domains — racks, switches, AZs, or sites.
- Replication: Use data replication strategies aligned to RPO/RTO requirements.
- Recovery: Automate health checks, failover orchestration, and configuration management.
- Review: Regularly test failover, update runbooks, and perform post-incident reviews.
High availability server setup strategies
Common strategies include load-balanced clusters for stateless workloads, master-slave or multi-master database replication, and container orchestration platforms that manage restart and rescheduling. For stateful services, use session stores or sticky sessions with cross-node replication to avoid user-impact during failover.
Practical implementation example
Scenario: a small e-commerce site needs 99.95% uptime. Implement a multi-AZ deployment with an active-active web layer behind a load balancer, database primary in one AZ with asynchronous replica in another for disaster recovery, and object storage replicated between sites. Health checks on the load balancer detect node failures and remove unhealthy hosts. Continuous configuration management ensures new nodes are provisioned identically. Regular disaster recovery drills validate RTO and RPO assumptions.
Practical tips
- Automate provisioning and recovery with infrastructure-as-code so rebuilds are consistent and auditable.
- Monitor both system metrics and business-level indicators (e.g., checkout completion rate) to identify partial degradations.
- Use chaos testing in a controlled manner to validate failover paths and uncover hidden dependencies.
- Keep runbooks and playbooks current and store them in a versioned, accessible location.
Trade-offs and common mistakes
Adding redundancy increases complexity, cost, and operational overhead. Common mistakes include:
- Assuming redundancy at one layer eliminates the need for checks at other layers — e.g., replicated storage doesn't help if both servers rely on the same power feed.
- Not validating failover procedures: untested failover often fails due to configuration drift or missing automation steps.
- Over-replicating without considering consistency requirements: synchronous replication can harm performance, while asynchronous replication can lead to data loss during a failover.
Verification and testing
Regular testing is critical. Include unit, integration, and disaster recovery tests. Use staged failover, simulated load, and intermittent fault injection. Track metrics such as failover time (time from failure to restored service), data loss (if any), and the frequency of false positives in health checks.
Compliance, standards, and documentation
Design decisions should reference operational standards and contingency planning best practices. For formal guidance on contingency planning and recovery testing, consult authoritative sources such as the NIST contingency planning publication (SP 800-34) for structured processes and control considerations: NIST SP 800-34 Rev. 1.
Core cluster questions
- How to choose between active-active and active-passive architectures?
- What is the right replication method for low RPO requirements?
- How often should failover drills be scheduled and what should they cover?
- Which monitoring metrics best indicate partial outages vs full outages?
- How to limit blast radius when a node or service fails?
Named framework recap: 4R Redundancy Framework
Use the 4R Redundancy Framework as a practical checklist during design reviews:
- Redundancy — ensure duplicate components across failure domains.
- Replication — match replication mode to recovery objectives.
- Recovery — automate detection and orchestration for failover and rebuilds.
- Review — schedule tests, audits, and updates to configurations and runbooks.
Common operational KPIs
Track mean time to detection (MTTD), mean time to recovery (MTTR), failover success rate, and customer-facing availability. Use these KPIs to prioritize investments in automation and redundancy.
Conclusion
Designing redundant server infrastructure is an exercise in aligning risk tolerance, budget, and operational maturity. Use the 4R framework, test regularly, and automate recovery wherever possible to reduce manual errors during incidents.
FAQ: What is redundant server infrastructure?
Redundant server infrastructure refers to design patterns that duplicate or distribute critical components so service continues when individual parts fail. This includes redundant servers, replicated storage, multiple network paths, and multi-site deployments.
FAQ: How do high availability server setup decisions affect cost?
Higher availability typically requires additional components, licenses, and operational overhead. Balance cost against required uptime and business impact; use targeted redundancy for highest-risk components first.
FAQ: How often should failover and recovery tests be performed?
At minimum, perform quarterly tests for major components and more frequent tests for critical-path services. Include automated smoke tests after failover to validate functional behavior.
FAQ: How to measure success of a redundant server infrastructure?
Measure MTTD, MTTR, failover success rate, and availability percentage. Also track business metrics like conversion rate or transaction throughput during and after incidents.
FAQ: Are there standard references for redundancy and contingency planning?
Yes. Use standards and guidance such as NIST SP 800-34 for contingency planning, and platform-specific best practices from major cloud vendors and infrastructure vendors for implementation details.