 Press Releases That Rank – Boost Authority & Brand Trust Fast!
Press Releases That Rank – Boost Authority & Brand Trust Fast!
Written by TeachAhead » Updated on: October 29th, 2024
Imagine having an ultra-intelligent assistant ready to answer any question. Now, imagine making it even more capable, specifically for tasks you rely on most. That’s the power—and the debate—behind Retrieval-Augmented Generation (RAG) and Fine-Tuning. These methods act as “training wheels,” each enhancing your AI’s capabilities in unique ways.
RAG brings in current, real-world data whenever the model needs it, perfect for tasks requiring constant updates. Fine-Tuning, on the other hand, ingrains task-specific knowledge directly into the model, tailoring it to your exact needs. Selecting between them can dramatically influence your AI’s performance and relevance.
Whether you’re building a customer-facing chatbot, automating tailored content, or optimizing an industry-specific application, choosing the right approach can make all the difference.
This guide will delve into the core contrasts, benefits, and ideal use cases for RAG and Fine-Tuning, helping you pinpoint the best fit for your AI ambitions.
Key Takeaways:
Retrieval-Augmented Generation (RAG) and Fine-Tuning are two powerful techniques for enhancing Large Language Models (LLMs) with distinct advantages.
RAG is ideal for applications requiring real-time information updates, leveraging external knowledge bases to deliver relevant, up-to-date responses.
Fine-Tuning excels in accuracy for specific tasks, embedding task-specific knowledge directly into the model’s parameters for reliable, consistent performance.
Hybrid approaches blend the strengths of both RAG and Fine-Tuning, achieving a balance of real-time adaptability and domain-specific accuracy.
What is RAG?
Retrieval-Augmented Generation (RAG) is an advanced technique in natural language processing (NLP) that combines retrieval-based and generative models to provide highly relevant, contextually accurate responses to user queries. Developed by OpenAI and other leading AI researchers, RAG enables systems to pull information from extensive databases, knowledge bases, or documents and use it as part of a generated response, enhancing accuracy and relevance.
How RAG Works?
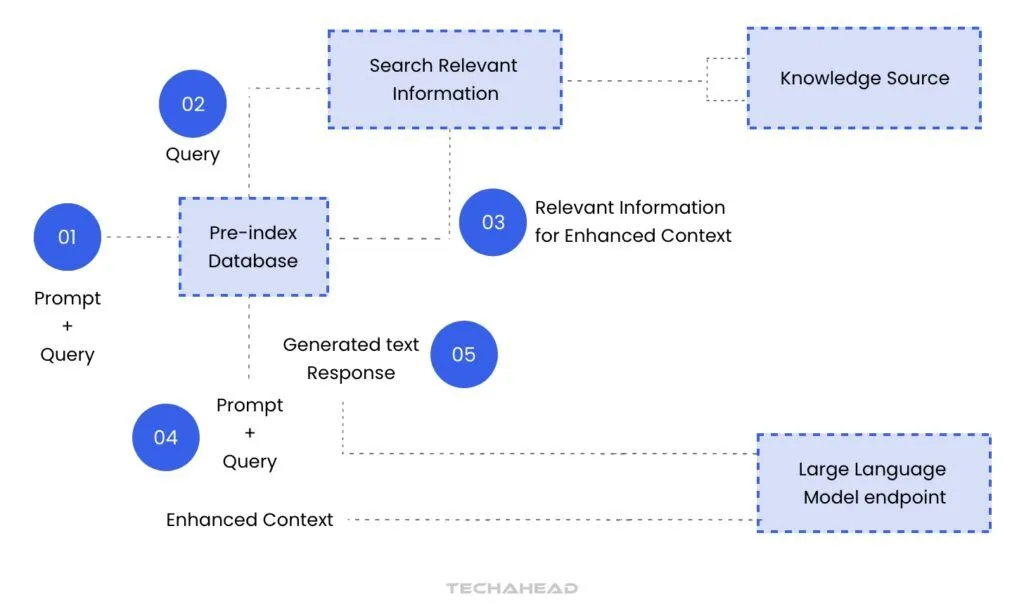
Retrieval Step
When a query is received, the system searches through a pre-indexed database or corpus to find relevant documents or passages. This retrieval process typically uses dense embeddings, which are vector representations of text that help identify the most semantically relevant information.
Generation Step
The retrieved documents are then passed to a generative model, like GPT or a similar transformer-based architecture. This model combines the query with the retrieved information to produce a coherent, relevant response. The generative model doesn’t just repeat the content but rephrases and contextualizes it for clarity and depth.
Combining Outputs
The generative model synthesizes the response, ensuring that the answer is not only relevant but also presented in a user-friendly way. The combined information often makes RAG responses more informative and accurate than those generated by standalone generative models.
Advantages of RAG

Improved Relevance
By incorporating external, up-to-date sources, RAG generates more contextually accurate responses than traditional generative models alone.
Reduced Hallucination
One of the significant issues with purely generative models is “hallucination,” where they produce incorrect or fabricated information. RAG mitigates this by grounding responses in real, retrieved content.
Scalability
RAG can integrate with extensive knowledge bases and adapt to vast amounts of information, making it ideal for enterprise and research applications.
Enhanced Context Understanding
By pulling from a wide variety of sources, RAG provides a richer, more nuanced understanding of complex queries.
Real-World Knowledge Integration
For companies needing up-to-date or specialized information (e.g., medical databases, and legal documents), RAG can incorporate real-time data, ensuring the response is as accurate and current as possible.
Disadvantages of RAG
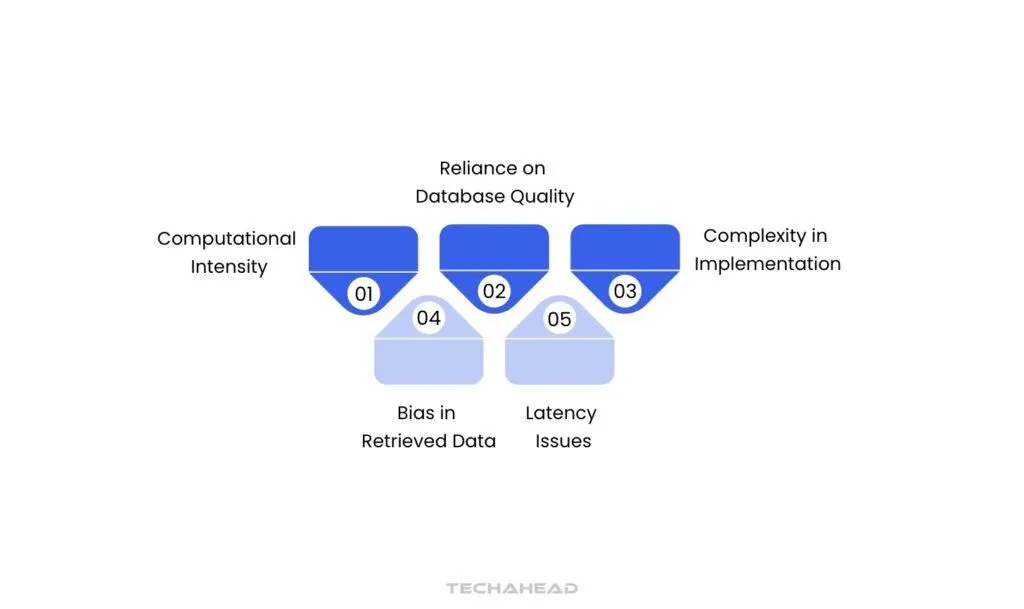
Computational Intensity
RAG requires both retrieval and generation steps, demanding higher processing power and memory, making it more expensive than traditional NLP models.
Reliance on Database Quality
The accuracy of RAG responses is highly dependent on the quality and relevance of the indexed knowledge base. If the corpus lacks depth or relevance, the output can suffer.
Latency Issues
The retrieval and generation process can introduce latency, potentially slowing response times, especially if the retrieval corpus is vast.
Complexity in Implementation
Setting up RAG requires both an effective retrieval system and a sophisticated generative model, increasing the technical complexity and maintenance needs.
Bias in Retrieved Data
Since RAG relies on existing data, it can inadvertently amplify biases or errors present in the retrieved sources, affecting the quality of the generated response.
What is Fine-Tuning?
Fine-tuning is a process in machine learning where a pre-trained model (one that has been initially trained on a large dataset) is further trained on a more specific, smaller dataset. This step customizes the model to perform better on a particular task or within a specialized domain. Fine-tuning adjusts the weights of the model so that it can adapt to nuances in the new data, making it highly relevant for specific applications, such as medical diagnostics, legal document analysis, or customer support.
How Fine-Tuning Works?
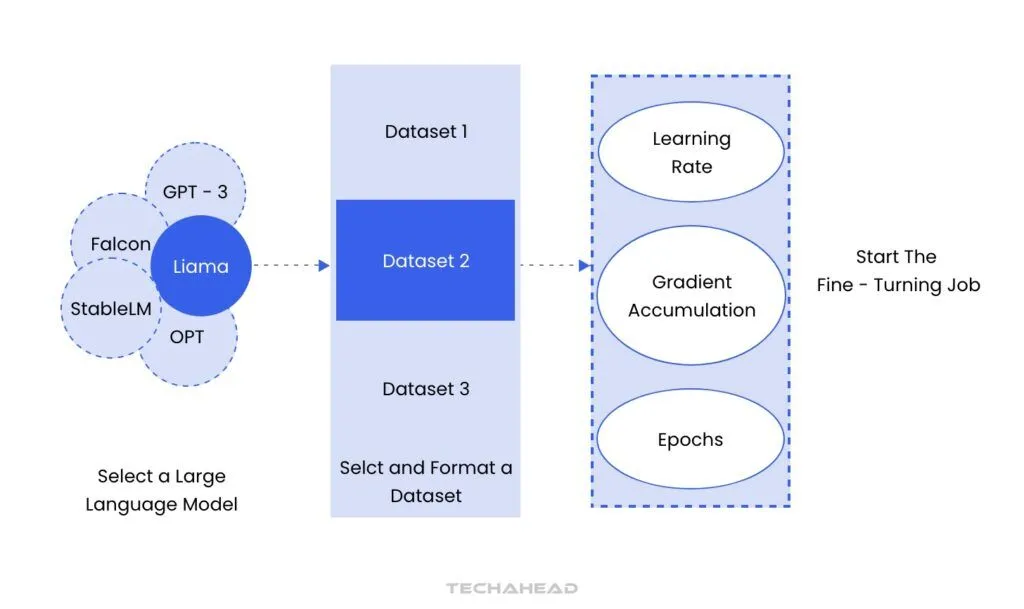
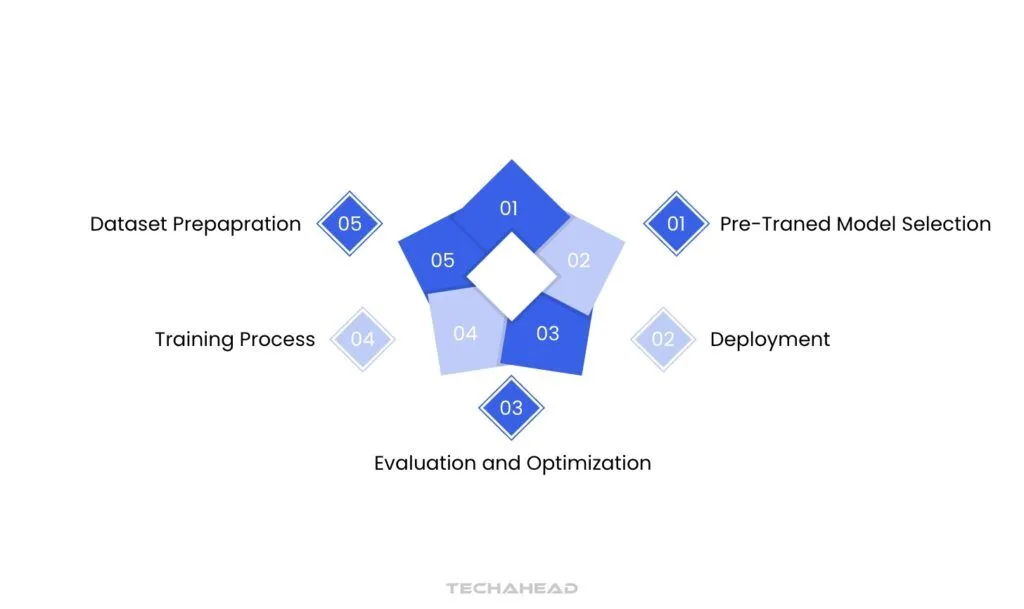
Pre-Trained Model Selection
A model pre-trained on a large, general dataset (like GPT trained on a vast dataset of internet text) serves as the foundation. This model already understands a wide range of language patterns, structures, and general knowledge.
Dataset Preparation
A specific dataset, tailored to the desired task or domain, is prepared for fine-tuning. This dataset should ideally contain relevant and high-quality examples of what the model will encounter in production.
Training Process
During fine-tuning, the model is retrained on the new dataset with a lower learning rate to avoid overfitting. This step adjusts the pre-trained model’s weights so that it can capture the specific patterns, terminology, or context in the new data without losing its general language understanding.
Evaluation and Optimization
The fine-tuned model is tested against a validation dataset to ensure it performs well. If necessary, hyperparameters are adjusted to further optimize performance.
Deployment
Once fine-tuning yields satisfactory results, the model is ready for deployment to handle specific tasks with improved accuracy and relevancy.
Advantages of Fine-Tuning
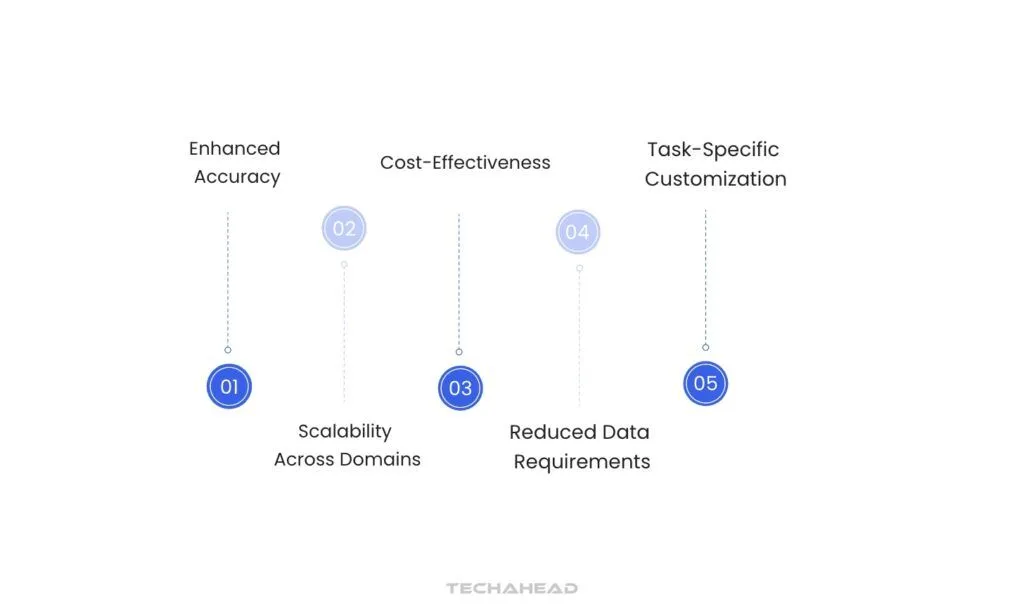
Enhanced Accuracy
Fine-tuning significantly improves the model’s performance on domain-specific tasks since it adapts to the unique vocabulary and context of the target domain.
Cost-Effectiveness
It’s more cost-effective than training a new model from scratch. Leveraging a pre-trained model saves computational resources and reduces time to deployment.
Task-Specific Customization
Fine-tuning enables customization for niche applications, like customer service responses, medical diagnostics, or legal document summaries, where specialized vocabulary and context are required.
Reduced Data Requirements
Fine-tuning typically requires a smaller dataset than training a model from scratch, as the model has already learned fundamental language patterns from the pre-training phase.
Scalability Across Domains
The same pre-trained model can be fine-tuned for multiple specialized tasks, making it highly adaptable across different applications and industries.
Disadvantages of Fine-Tuning
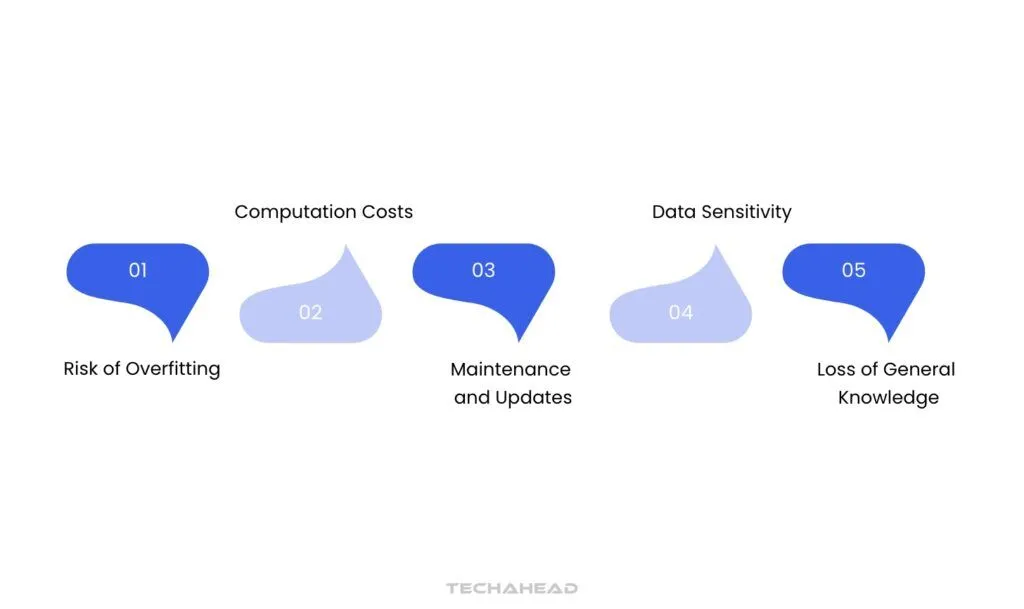
Risk of Overfitting
If the fine-tuning dataset is too small or lacks diversity, the model may overfit, meaning it performs well on the fine-tuning data but poorly on new inputs.
Loss of General Knowledge
Excessive fine-tuning on a narrow dataset can lead to a loss of general language understanding, making the model less effective outside the fine-tuned domain.
Data Sensitivity
Fine-tuning may amplify biases or errors present in the new dataset, especially if it’s not balanced or representative.
Computation Costs
While fine-tuning is cheaper than training from scratch, it still requires computational resources, which can be costly for complex models or large datasets.
Maintenance and Updates
Fine-tuned models may require periodic retraining or updating as new domain-specific data becomes available, adding to maintenance costs.
Key Difference Between RAG and Fine-Tuning
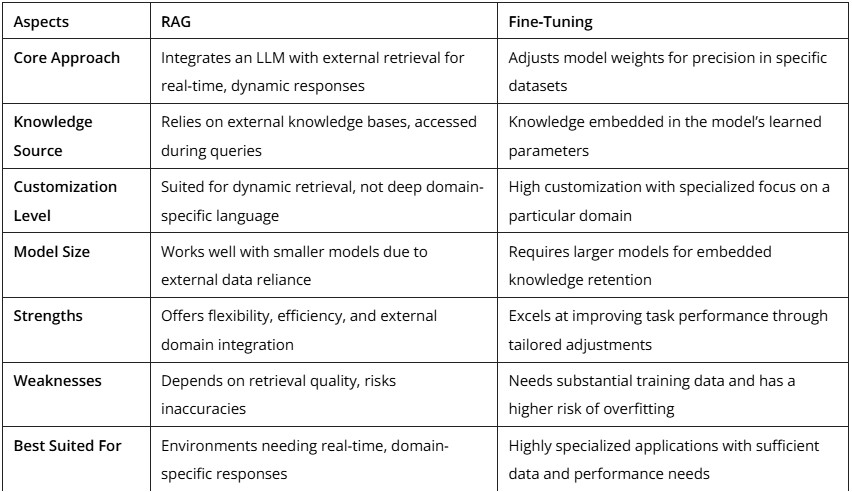
Key Trade-Offs to Consider
Data Dependency
RAG’s dynamic data retrieval means it’s less dependent on static data, allowing accurate responses without retraining.
Cost and Time
Fine-tuning is computationally demanding and time-consuming, yet yields highly specialized models for specific use cases.
Dynamic Vs Static Knowledge
RAG benefits from dynamic, up-to-date retrieval, while fine-tuning relies on stored static knowledge, which may age.
When to Choose Between RAG and Fine-Tuning?
RAG shines in applications needing vast and frequently updated knowledge, like tech support, research tools, or real-time summarization. It minimizes retraining requirements but demands a high-quality retrieval setup to avoid inaccuracies. Example: A chatbot using RAG for product recommendations can fetch real-time data from a constantly updated database.
Fine-tuning excels in tasks needing domain-specific knowledge, such as medical diagnostics, content generation, or document reviews. While demanding quality data and computational resources, it delivers consistent results post-training, making it well-suited for static applications. Example: A fine-tuned AI model for document summarization in finance provides precise outputs tailored to industry-specific language.
the right choice is totally depended on the use case of your LLM chatbot. Take the necessary advantages and disadvantages in the list and choose the right fit for your custom LLM development.
Hybrid Approaches: Leveraging RAG and Fine-Tuning Together
Rather than favoring either RAG or fine-tuning, hybrid approaches combine the strengths of both methods. This approach fine-tunes the model for domain-specific tasks, ensuring consistent and precise performance. At the same time, it incorporates RAG’s dynamic retrieval for real-time data, providing flexibility in volatile environments.
Optimized for Precision and Real-Time Responsiveness

With hybridization, the model achieves high accuracy for specialized tasks while adapting flexibly to real-time information. This balance is crucial in environments that require both up-to-date insights and historical knowledge, such as customer service, finance, and healthcare.
Versatile, Cost-Effective Performance
Hybrid approaches maximize flexibility without extensive retraining, reducing costs in data management and computational resources. This approach allows organizations to leverage existing fine-tuned knowledge while scaling up with dynamic retrieval, making it a robust, future-proof solution.
Conclusion
Choosing between RAG and Fine-Tuning depends on your application’s requirements. RAG delivers flexibility and adaptability, ideal for dynamic, multi-domain needs. It provides real-time data access, making it invaluable for applications with constantly changing information.
Fine-Tuning, however, focuses on domain-specific tasks, achieving greater precision and efficiency. It’s perfect for tasks where accuracy is non-negotiable, embedding knowledge directly within the model.
Hybrid approaches blend these benefits, offering the best of both. However, these solutions demand thoughtful integration for optimal performance, balancing flexibility with precision.
At TechAhead, we excel in delivering custom AI app development around specific business objectives. Whether implementing RAG, Fine-Tuning, or a hybrid approach, our expert team ensures AI solutions drive impactful performance gains for your business.
Source URL: https://www.techaheadcorp.com/blog/rag-vs-fine-tuning-difference-for-chatbots/
Disclaimer: We do not promote, endorse, or advertise betting, gambling, casinos, or any related activities. Any engagement in such activities is at your own risk, and we hold no responsibility for any financial or personal losses incurred. Our platform is a publisher only and does not claim ownership of any content, links, or images unless explicitly stated. We do not create, verify, or guarantee the accuracy, legality, or originality of third-party content. Content may be contributed by guest authors or sponsored, and we assume no liability for its authenticity or any consequences arising from its use. If you believe any content or images infringe on your copyright, please contact us at support@indibloghub.com for immediate removal.
Sponsored Ad Partners


![]()

Copyright © 2019-2025 IndiBlogHub.com. All rights reserved. Hosted on DigitalOcean for fast, reliable performance.
