The Ultimate Guide to Integrating Agentic RAG into Your Enterprise Workflow
-

- May 08th, 2026
- 522 views

Get a free topical map and start building content authority today.
Agentic RAG (Retrieval-Augmented Generation) marks a significant advancement in AI, combining large language models (LLMs) with intelligent retrieval systems and autonomous agent capabilities. For enterprises striving to maintain a competitive edge, integrating Agentic RAG can streamline operations, enhance decision-making, and improve user experiences. This guide walks through how enterprises can seamlessly implement Agentic RAG into their workflows to unlock its full potential.
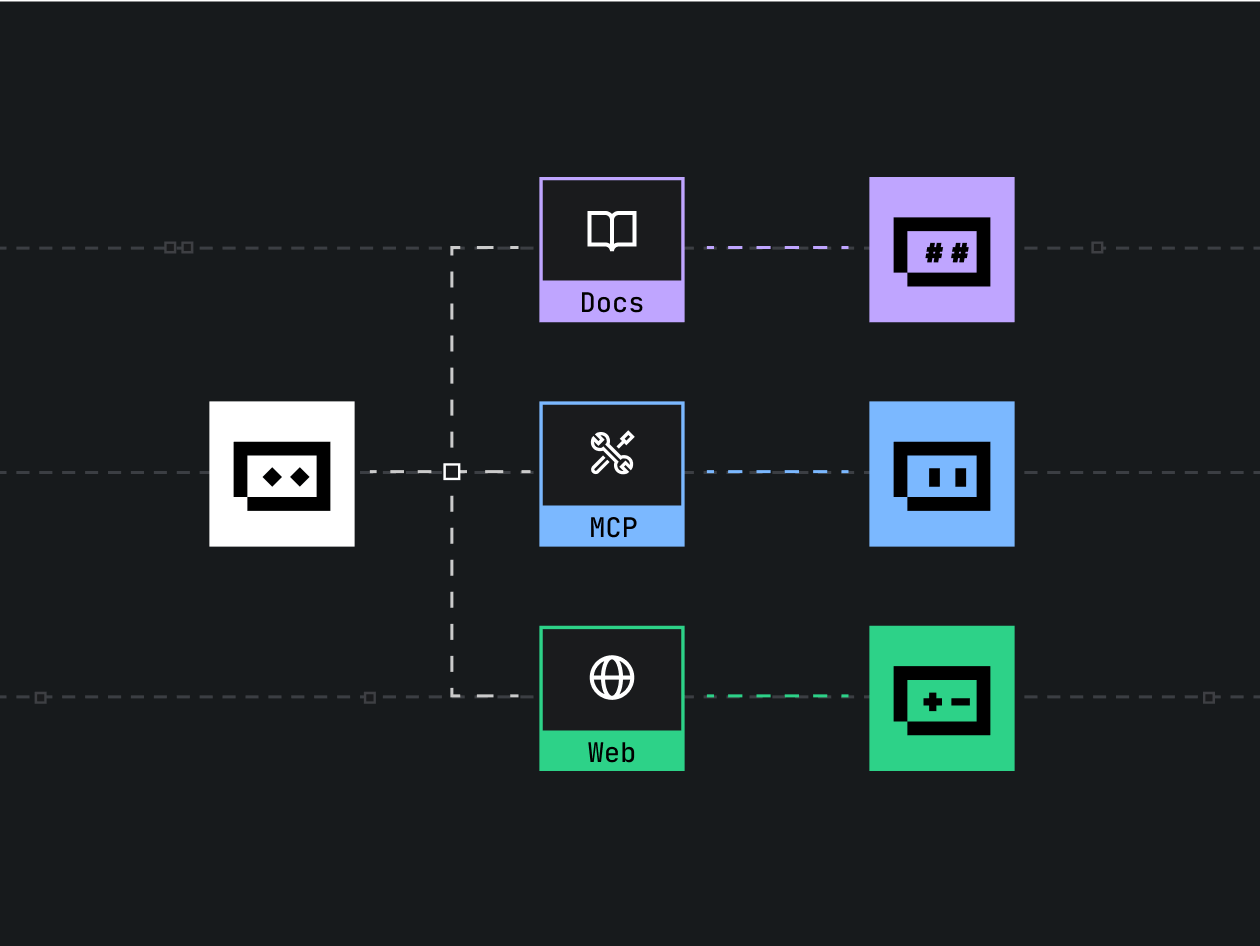
Understanding Agentic RAG and Its Mechanisms
Agentic RAG is an evolution of the traditional RAG model, integrating autonomous agents into the retrieval and generation loop. This enhancement allows systems to not only retrieve and generate information but also to autonomously act on it. Here’s a breakdown of how each component collaborates:
Retrieval System
The retrieval system serves as the backbone of the Agentic RAG architecture. It organizes internal and external data sources, such as company databases, document storage, intranets, APIs, and online content. Unlike traditional keyword matching, the retrieval system uses dense vector embeddings to find semantically relevant information, thereby improving accuracy and relevance. Tools like Pinecone, Weaviate, and FAISS are often employed in this process.
This layer ensures that the system has access to the most pertinent and current information, reducing the chances of misinformation and improving factual precision.
Generation Model
The generation model, typically a large language model (LLM) such as GPT-4 by OpenAI or Claude by Anthropic, produces responses based on the documents retrieved. Unlike traditional models, the generation system in Agentic RAG operates within the context of the retrieved content. This approach guarantees that the generated responses are accurate, domain-specific, and in line with the company’s objectives.
Fine-tuning the model using enterprise-specific data and prompts ensures that outputs are customized according to the company’s voice, compliance standards, and business needs. This makes it ideal for tasks such as customer support, internal knowledge management, or document summarization.
Autonomous Agents
Autonomous agents are what make Agentic RAG truly dynamic. These agents serve as orchestrators, making decisions based on real-time data, managing tasks, interacting with APIs, and initiating follow-up actions as needed.
Each agent plays a distinct role:
- Retriever Agent: Fetches the relevant documents from databases.
- Planner Agent: Evaluates the retrieved data and determines the next steps.
- Executor Agent: Takes action, such as updating a CRM or scheduling an event.
In a customer service environment, for instance, an agent might pull up a customer’s previous interactions, evaluate their sentiments, generate an appropriate response, and automatically update the CRM—all within a matter of seconds.
These agents operate using logic trees, reinforcement learning, or prompt chaining. They can also escalate tasks to human operators if their confidence level is insufficient. Over time, these agents can improve through feedback loops and more data.
Why Should Enterprises Implement Agentic RAG?
Enterprises can achieve numerous benefits by integrating Agentic RAG:
- Accelerated Decision-Making: Provides accurate, context-driven answers without the need for manual research.
- Efficient Knowledge Access: Consolidates structured and unstructured data, supporting more complex queries.
- Enhanced Automation: Autonomous agents can take actions based on insights, such as updating systems or triggering alerts.
- Scalability: Easily deployable across various departments like HR, finance, legal, and customer support.
Industries including finance, healthcare, retail, and manufacturing are already adopting Agentic RAG to drive innovation. Furthermore, it helps employees by offloading repetitive tasks, allowing them to focus on higher-level, strategic activities.
Pre-Integration Considerations
Before deploying Agentic RAG, enterprises should:
- Evaluate Infrastructure: Ensure the environment is optimized for AI workloads (cloud or hybrid).
- Ensure Data Readiness: Consolidate siloed data sources and establish clear data access guidelines.
- Assess Skill Sets: Hire or train professionals with expertise in machine learning, data science, and AI operations.
- Compliance and Security: Implement governance measures that align with industry-specific regulations (e.g., GDPR, HIPAA).
Check Integration Readiness: Ensure compatibility with existing enterprise systems like CRMs, ERPs, and DMS.
A thorough pre-integration phase should also include risk assessment, creating sandbox environments, and conducting early-stage tests to understand how Agentic RAG will interact with the current digital infrastructure.
Step-by-Step Guide for Integration
1. Define Objectives and Use Cases
- Identify high-value workflows (e.g., customer support, document management).
- Align specific use cases with key performance indicators (KPIs) and organizational goals.
2. Data Preparation and Cleansing
- Organize unstructured data.
- Generate embeddings with vector databases such as Pinecone or Weaviate.
The focus should also be on ensuring data freshness, with time-sensitive data being regularly updated for continued relevance.
3. Choosing the Right Agentic RAG Architecture
- Select between open-source (e.g., LangChain, Haystack) or proprietary frameworks.
- Assess compatibility with the preferred LLMs (e.g., GPT-4, Claude).
The architecture should be evaluated based on performance, maintainability, long-term cost, and community support.
4. Building and Training the Retrieval System
- Create pipelines for document ingestion and indexing.
- Use similarity search algorithms for quick retrieval.
Ensure that the indexing mechanism accommodates enterprise-specific terminologies and taxonomies.
5. Fine-Tuning the Generation Model
- Link the retrieval system with the LLM.
- Refine the prompts and system behavior for domain-specific functions.
Incorporating feedback from stakeholders during prompt evaluation sessions can help fine-tune the model for optimal alignment with business requirements.
6. Developing Autonomous Agents
- Define the roles for each agent (retriever, planner, executor).
- Enable agents to interface with APIs and internal systems.
Consider introducing fallback mechanisms or human-in-the-loop (HITL) protocols for sensitive tasks.
7. Testing and Validation
- Perform internal QA and real-world scenario testing.
- Track metrics like response time, relevance, and accuracy.
A/B testing or shadow deployments can be used to reduce risks during the testing phase.
8. Deployment and Ongoing Monitoring
- Implement monitoring tools to track performance and model drift.
- Continuously iterate based on real-time feedback and shifting business needs.
Establish dashboards that track both technical performance and business outcomes (e.g., query resolution time).
Common Challenges and Their Solutions
Data Silos: Break down data silos using data integration platforms or shared data lakes.
Hallucinations: Improve accuracy with retrieval grounding and prompt optimization.
Security Issues : Adopt role-based access controls, implement audit trails, and use encryption.
Team Resistance: Provide hands-on training to teams and demonstrate early successes.
Challenges such as prompt injections and adversarial attacks can be mitigated using input sanitization techniques and anomaly detection models.
Best Practices for Sustaining Success
- Continuous Model Updates: Regularly retrain models with new data.
- Collaborate Across Teams: Involve cross-functional teams (IT, operations, domain experts) early on.
- Plan for Scalability: Use modular, cloud-native architecture.
- Integrate MLOps: Automate continuous integration and deployment (CI/CD) for model updates.
Maintaining detailed documentation and model cards ensures transparency and proper governance in enterprise settings.
The Future of Agentic RAG in Enterprise Workflows
- Multimodal RAG: Incorporating images, audio, and video alongside text.
- Self-Improving Agents: Agents that evolve and adapt based on usage.
- Comprehensive Automation: Full-scale automation of enterprise workflows with minimal human intervention.
Agentic RAG will likely see deeper integration with edge computing, allowing for efficient operation in on-premise or hybrid environments, crucial for latency-sensitive industries.
Conclusion
Agentic RAG represents the next frontier in enterprise AI, blending the power of retrieval, generation, and autonomy. By following this guide, enterprises can unlock smarter workflows, better decisions, and scalable automation.
With the right approach, organizations can ensure that their adoption of Agentic RAG is not just a technical upgrade but a strategic leap toward AI-driven enterprise transformation.