Real-Time Product Monitoring with Web Scraping APIs: Practical Guide
-

- March 03rd, 2026
- 286 views

Get a free topical map and start building content authority today.
Introduction
Choosing a web scraping API for real-time product monitoring requires understanding how APIs, proxies, and parsing strategies work together to deliver fast, accurate price and availability data. This guide explains the core approaches, defines key terms, and gives actionable steps to implement reliable monitoring with a web scraping API for real-time product monitoring.
- Goal: collect frequent, accurate product data (price, stock, variants) with minimal blocking.
- Core components: request orchestration, proxy/IP rotation, rendering (JS/headless), parsing, storage, and alerting.
- Quick action: start with a focused site list, use a proxy pool, respect robots.txt, and normalize data.
Detected intent: Informational
What is a web scraping API for real-time product monitoring?
A web scraping API for real-time product monitoring centralizes the tasks of fetching HTML, rendering JavaScript when required, and returning structured data (JSON, CSV) on product pages. It handles retries, user-agent rotation, and often integrates proxy management so that monitoring systems can retrieve price and availability updates at short intervals without building the entire scraping stack from scratch. Related terms: IP rotation, headless browser, proxy pool, rate limiting, CSS selectors, XPath, webhooks.
How these APIs fit into a monitoring system
Typical architecture: scheduler & queue -> scraping API or scraper cluster -> parsing & normalization -> database -> alerting/analytics. For true real-time needs, use streaming or webhook outputs from the scraping API into a message queue (Kafka, RabbitMQ, or cloud pub/sub) for downstream processing.
Types of scraping approaches
- Direct HTML fetch (fast, low overhead) — best when pages are server-rendered.
- Headless-browser rendering (Puppeteer/Playwright) — needed for heavy client-side JS.
- Hybrid: cached rendered snapshots plus selective re-renders for dynamic elements.
REAP checklist for real-time product monitoring
Use the REAP checklist to validate monitoring readiness:
- Respect: honor robots.txt and rate limits; handle opt-out pages sensibly. See the official standard: RFC 9309 (robots.txt).
- Endpoints: define exact URLs, API endpoints, and selectors for price, SKU, availability, and title.
- Access: configure proxy pool, IP rotation, and backoff strategies to reduce blocking.
- Processing: normalize currencies, timestamps, and variant mappings; maintain schema versioning.
Implementation steps (practical)
The following sequence guides a basic build using a web scraping API for real-time product monitoring:
- Inventory: list target product pages and APIs, identify dynamic elements that require rendering.
- Prototype: fetch a sample page through the scraping API, extract price, title, SKU, and availability selectors.
- Schedule: set polling cadence per site (e.g., every 1–5 minutes for high-priority SKUs, hourly for others) and implement jitter to avoid synchronized bursts.
- Normalize: convert price strings, currency, and availability flags into a canonical schema before storing.
- Alert & store: push changes to a time-series store or database and trigger alerts for significant deltas or out-of-stock events.
Short real-world example
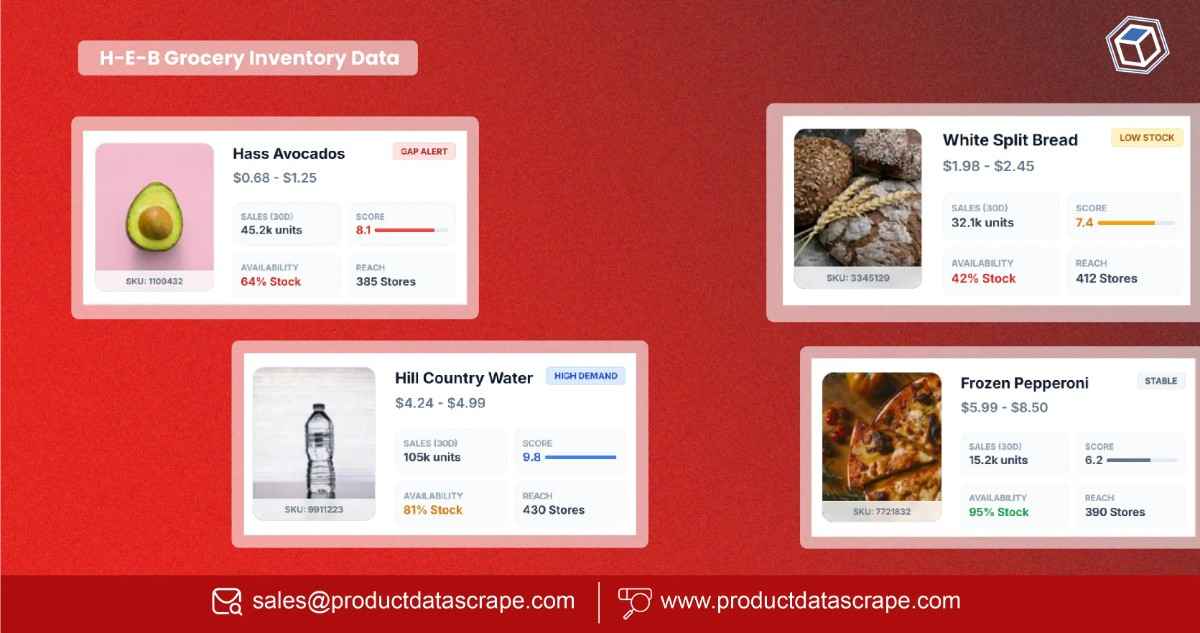
Scenario: a retailer needs near real-time competitor price updates for 2,000 SKUs across three marketplaces. Use a scraping API to render pages with product options, configure a proxy pool with regional endpoints, and poll high-velocity items every 2 minutes while batching lower-priority SKUs every 30 minutes. Normalize prices to a single currency, dedupe by SKU, and stream changes into a dashboard and threshold-based alerts.
Practical tips (3–5 tactical points)
- Start small: confirm selectors on a representative sample set before scaling to thousands of pages.
- Use exponential backoff: increase intervals for sites that return 429/403 to avoid permanent blocks.
- Cache intelligently: store snapshots and only re-render pages when key DOM elements change.
- Monitor request success rates and false positives for price detection to catch parsing regressions fast.
Trade-offs and common mistakes
Trade-offs:
- Speed vs. cost: higher polling frequency and headless rendering increase infrastructure and proxy costs.
- Accuracy vs. scale: more robust parsing (machine learning or DOM heuristics) improves accuracy but raises complexity.
Common mistakes:
- Not normalizing currency or time zones, which leads to misleading alerts.
- Polling everything at the same cadence — causes spikes and increases blocking risk.
- Ignoring robots.txt and legal restrictions — always document and follow applicable policies and terms of service.
Core cluster questions
- How to design a polling strategy for price monitoring?
- What proxy and IP rotation patterns reduce blocking during high-frequency scraping?
- How to detect and parse prices on JavaScript-rendered product pages?
- Best practices for normalizing price, currency, and availability data?
- How to scale scraping from a prototype to thousands of SKUs while maintaining accuracy?
Monitoring and maintenance
Set up observability: track request latency, error codes (403, 429, 500), parsing failure rate, and data drift. Implement automated selector validation against a baseline and schedule monthly audits of high-priority sites. Use feature flags to roll back changes without redeploying the entire pipeline.
Security and compliance considerations
Keep credentialed access (API keys, sessions) secure, rotate keys regularly, and limit data retention to what’s necessary. Consult legal counsel for jurisdictional scraping laws and make sure to respect robots.txt and API terms when required.
FAQ
What is a web scraping API for real-time product monitoring and when should it be used?
A web scraping API for real-time product monitoring is a managed or self-hosted interface that fetches and often renders web pages, then returns structured product data for near real-time use. Use it when existing public APIs are insufficient, product pages are the authoritative source, and updates must be tracked more frequently than manual checks allow.
How often can pages be polled without getting blocked?
There is no universal rate; safe polling depends on site policies, proxy diversity, and request patterns. Apply rate limits, add jitter, use rotating IPs, and respect 429/403 responses. Monitor site-specific tolerance and adapt.
Which parsing methods reliably extract prices and availability?
Start with CSS selectors/XPath for stable pages. For dynamic or inconsistent markup, use DOM heuristics (search for currency symbols, microdata/schema.org product properties) or lightweight ML classifiers to reduce false positives.
Can scraping APIs handle CAPTCHAs and JavaScript rendering?
Many scraping APIs offer headless rendering for JavaScript and integrations with CAPTCHA-solving services, but both increase costs and complexity. Prefer server-side fallbacks or manual review workflows where possible.
How to integrate changes from scraping into downstream systems?
Stream normalized JSON to a message queue or webhook endpoint, version the schema, and include metadata (timestamp, source URL, request id). Consumers should implement idempotency and reconcile updates with historical records.