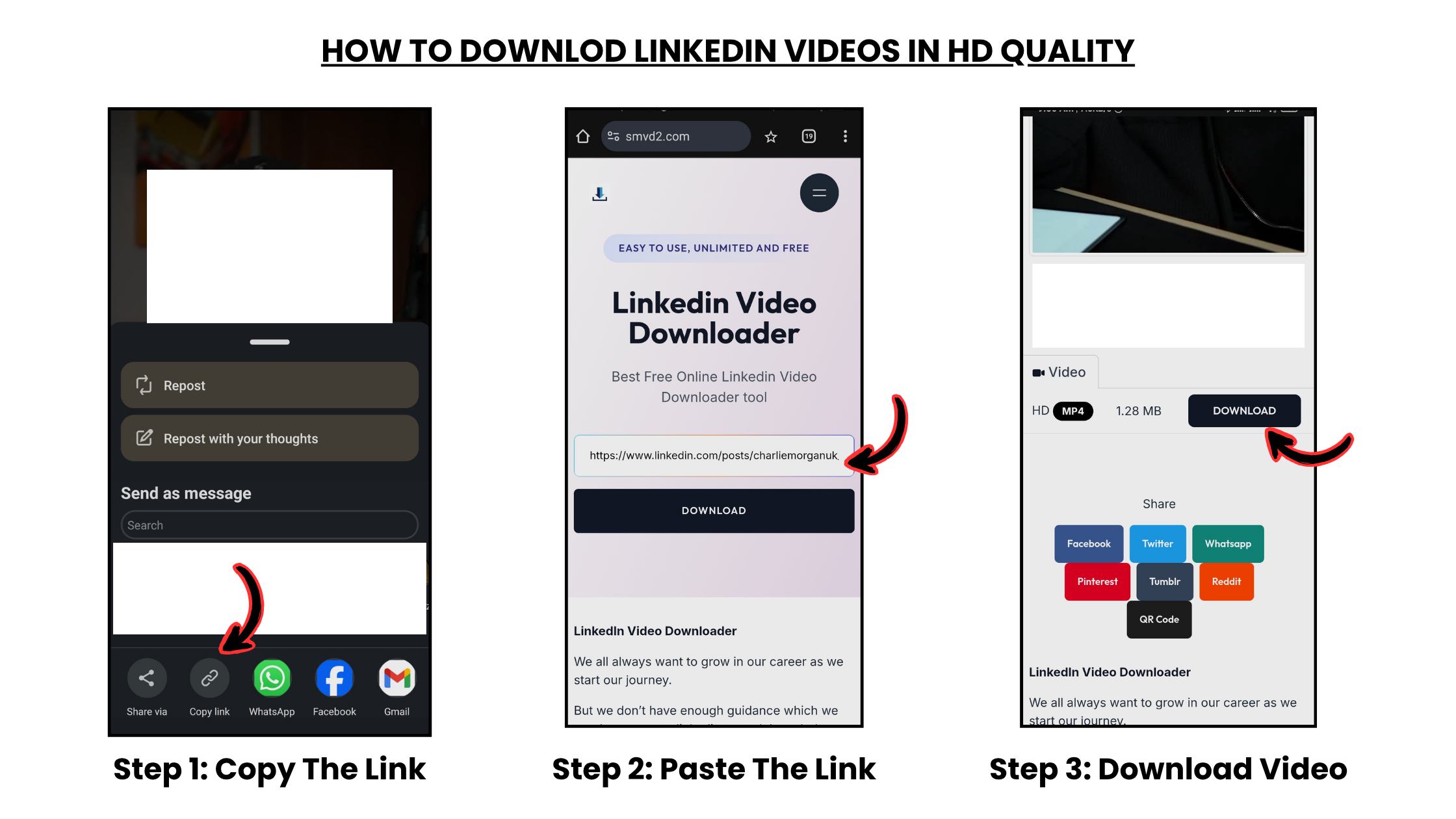
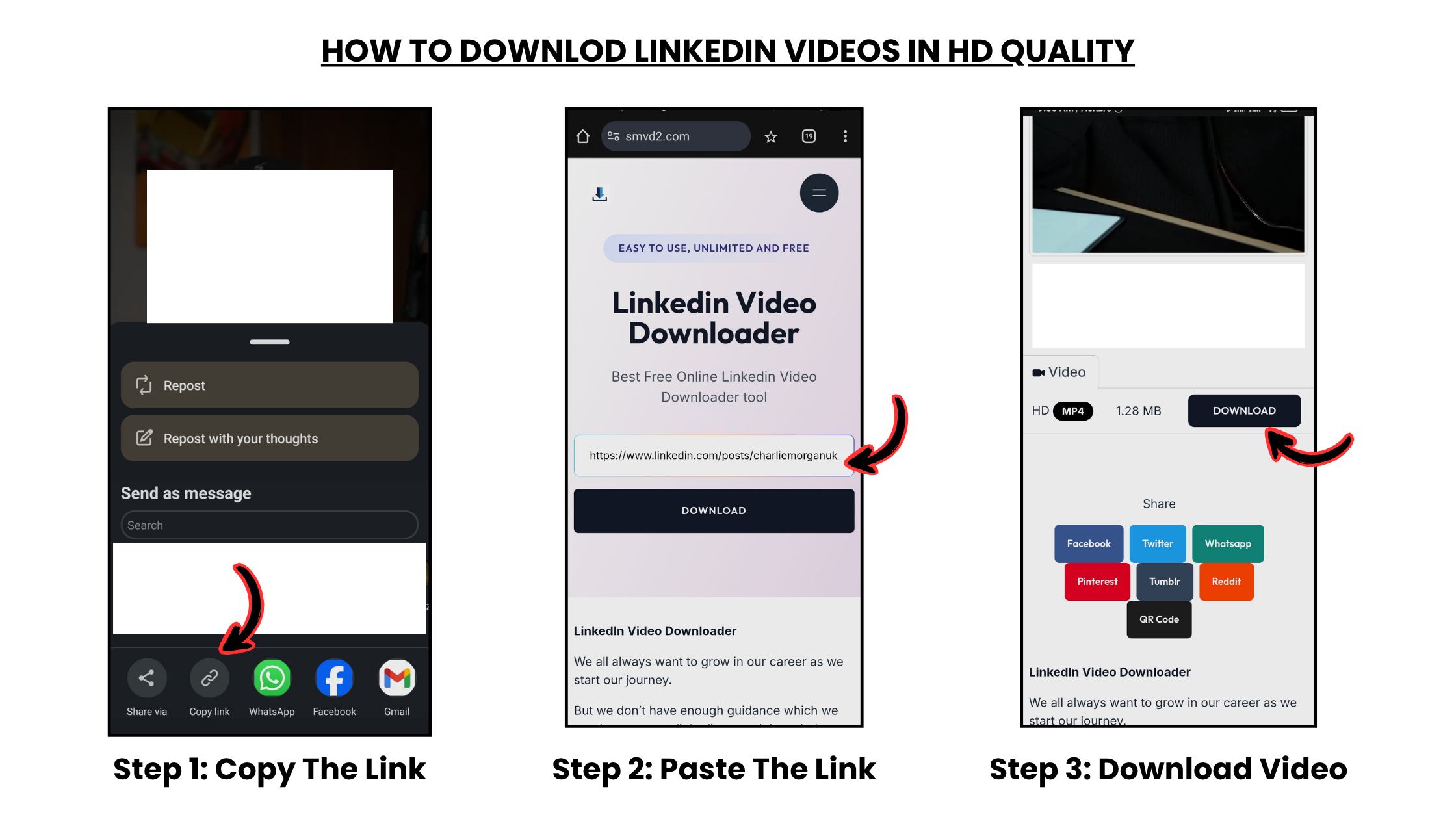
How to Choose an Audio Transcription Tool for Podcast and Video Content
-

- March 26th, 2026
- 128 views


FREE SEO Topical Map Generator: Find Your Next Content Ideas
Selecting the right audio transcription tool starts with the content goals: searchable show notes, on-screen captions, SEO-ready blog posts, or compliance-grade verbatim records. The primary decision criteria are accuracy, speaker handling, timestamping, format exports, and how the tool fits into an editing or publishing workflow. This article compares common approaches and trade-offs to help choose an audio transcription tool for podcast and video content text that fits specific production needs.
What counts when comparing an audio transcription tool
Compare models on measurable features: word error rate (WER) or accuracy under realistic conditions, speaker diarization quality, timestamp granularity, supported file formats, language coverage, API and automation capabilities, and export options (SRT, VTT, TXT, DOCX). Also confirm data handling policies, retention rules, and options for on-premise or private cloud processing if confidentiality matters.
Types of solutions and trade-offs
Fully automated ASR engines
Automatic speech recognition (ASR) services are the fastest and cheapest option. They provide near-instant transcripts and broad language support. Trade-offs: accuracy drops on low-quality audio, overlapping speakers, or heavy accents; expect editing time for publication-ready text.
Human or hybrid transcription services
Human editors or hybrid workflows (machine draft + human correction) produce higher accuracy, better speaker labels, and cleaner punctuation. These options cost more and have higher turnaround time but reduce post-edit effort, which can be essential for legal or highly polished content.
On-premise or self-hosted models
Self-hosted speech-to-text models offer control over data and potential cost savings at scale. Setup and maintenance require technical resources. They are a strong fit when privacy, custom acoustic models, or local language variants are critical.
Key features to prioritize for podcast transcription software
For podcasts and video, prioritize these features: accurate speaker diarization, word-level timestamps, support for SRT/VTT for captions, searchable timestamps for show notes, noise-robust models, and easy export to editing tools or CMS platforms. Integration capability (APIs, Zapier, or direct CMS plugins) reduces manual steps and speeds publishing. Also check for punctuation and capitalization handling and the ability to recognize branded or domain-specific vocabulary.
TRANSCRIBE Checklist (named framework)
Use the TRANSCRIBE Checklist when evaluating tools:
- Timestamps: Word-level vs. line-level, required granularity
- Recognition: Measured accuracy or WER on similar audio
- Accuracy boosts: Noise reduction, custom vocabularies
- Speaker labels: Diarization and manual correction options
- Support formats: SRT, VTT, TXT, DOCX, JSON
- Compliance: Data handling, retention, encryption
- Reliability: Uptime, batch processing, API limits
- Ease of integration: CMS, editing tools, automation
- Backup and exports: Version history and raw audio linkage
Real-world example
A 45-minute interview podcast uses an automated engine to generate a draft transcript with speaker diarization and timestamps. The editor imports the transcript into a text editor, corrects speaker names and misheard phrases, and exports SRT for the YouTube upload. The corrected transcript is repurposed into blog show notes with chapter timestamps and a searchable episode page—reducing manual note-taking time by two-thirds while retaining editorial control.
Practical tips for getting accurate transcripts
- Record with a decent microphone and separate tracks for guests when possible; multitrack audio improves diarization and accuracy.
- Use in-line noise reduction and normalize levels before transcription to improve ASR results.
- Provide a custom vocabulary or proper names list to the tool when available to reduce error on brand or guest names.
- Automate the first pass, then assign a human editor for final polish when publishing to high-visibility channels.
- Batch-process archives overnight using APIs to build searchable episode libraries efficiently.
Common mistakes and trade-offs
Choosing speed over accuracy without a correction step can damage discoverability and viewer experience—auto captions with high error rates reduce comprehension and accessibility. Conversely, choosing highest-accuracy human services for every episode is often cost-inefficient. Balance depends on the content's purpose: internal notes and rough drafts tolerate more ASR errors; public captions and SEO content require higher accuracy.
Also watch out for privacy trade-offs: free cloud services may retain audio for model training. For confidentiality, prefer tools with clear retention policies or self-hosted options.
Accessibility and standards
Accurate transcripts and captions improve accessibility and help meet guidelines from standards bodies. Follow captioning and transcript best practices from accessibility organizations to ensure usable output; see the W3C guidance on media accessibility for recommended approaches and formats: W3C media accessibility guidance.
Selecting the best fit
Match tool choice to output need: choose a low-cost automated engine for draft transcripts and internal search; choose hybrid or human services for publishing-ready captions and legal transcripts; choose self-hosted models when data control and customization are the highest priority. Factor in integration and automation to minimize manual steps.
FAQ: which audio transcription tool questions
Which audio transcription tool produces the most accurate podcast transcripts?
Accuracy varies with audio quality, language, and accents. Hybrid services (machine draft plus human proofing) typically produce the most accurate final transcripts. For sensitivity and legal needs, certified human transcription or services with quality audits are preferable.
How much does podcast transcription software usually cost?
Costs range from cents per minute for automated services to $1–$3+ per minute for human transcription. Subscription plans, monthly minutes bundles, and enterprise pricing with SLAs are common—choose based on monthly volume and required turnaround time.
Can video transcription for captions be automated reliably?
Automated caption generation is reliable for clear audio and single speakers; however, manual review is recommended for overlapping speech, music-heavy segments, or content requiring exact timing and legal accuracy.
How to integrate automatic speech-to-text for podcasts into a publishing workflow?
Use tools with API access or direct CMS plugins to automate ingestion, generate drafts, and trigger human review steps. Export SRT/VTT for platforms like YouTube and tie transcripts to episode pages for SEO benefits.
Are transcripts usable for SEO and repurposing content?
Yes—clean, edited transcripts improve search visibility, enable quotes for show notes, and support repurposing into articles, social posts, and metadata. Ensure transcripts are edited for readability and include timestamps and speaker labels where useful.