Building Multimodal AI Agents in 2025: Practical Guide for Voice, Text & Vision Systems
-

- March 01st, 2026
- 337 views

Get a free topical map and start building content authority today.
Introduction: What building multimodal AI agents looks like in 2025
Multimodal AI agents combine voice, text and vision to interact with users and environments. This guide explains how multimodal AI agents are designed and deployed in 2025, covering architecture patterns, data and evaluation, safety controls, and practical trade-offs. Detected intent: Informational
- Core components: signal capture (ASR, camera), modality encoders (LMs, vision transformers), fusion layers, policy and safety layers.
- MAVIS checklist for project readiness: Modality, Architecture, Validation, Integration, Safety.
- Focus on latency, privacy, and aligned behavior; use canonical evaluation metrics and continuous monitoring.
Multimodal AI agents: What they are and how they work
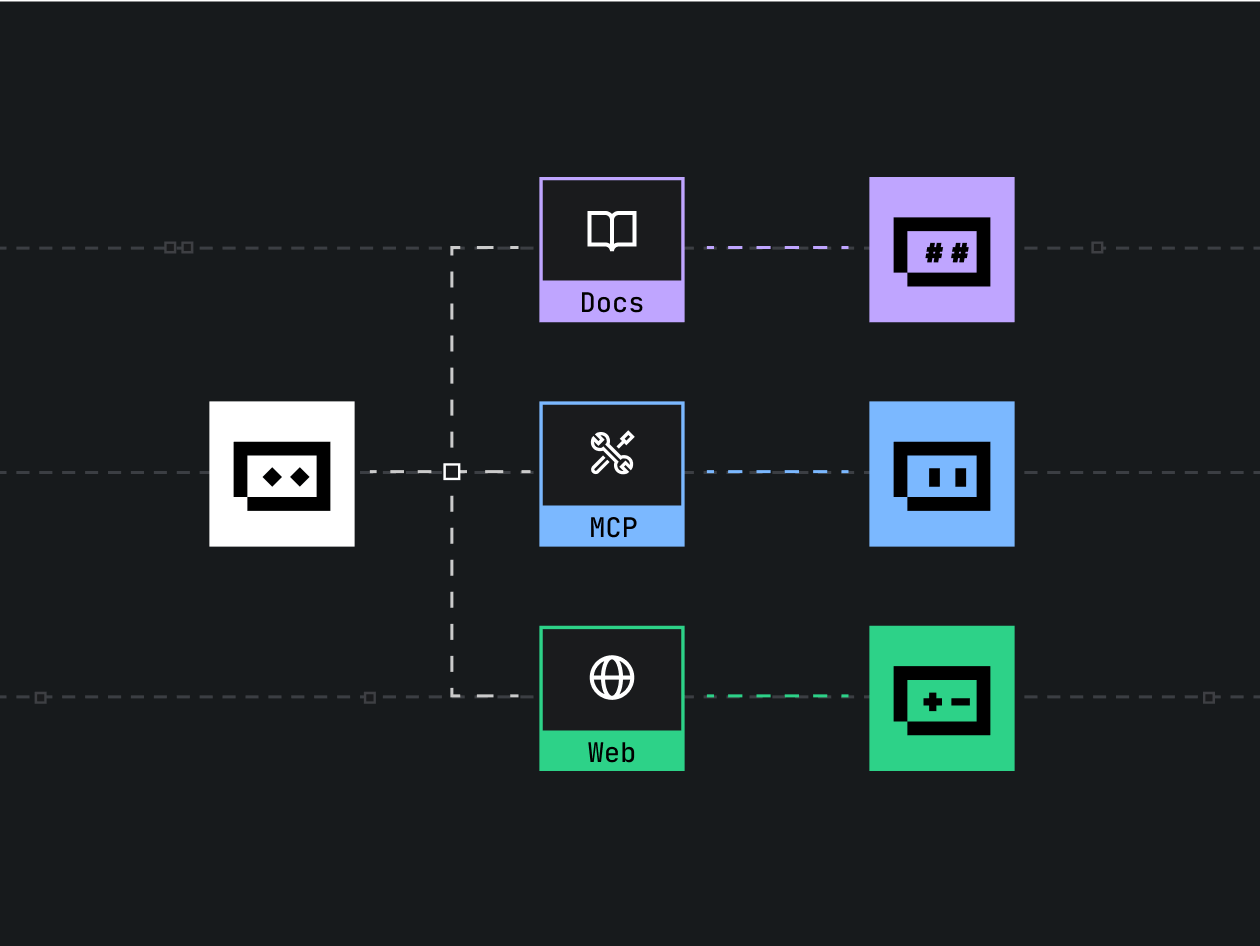
At a high level, multimodal AI agents are systems that sense and act using multiple input and output types—commonly voice (automatic speech recognition and speech synthesis), text (language models and retrieval), and vision (image recognition, OCR, object detection). Building a production-ready multimodal agent requires integrating perception stacks, a central reasoning or policy model, and execution connectors for downstream services or actuators.
Core architecture and components for multimodal agent architecture
Perception modules (voice, text, vision)
Perception converts raw signals into structured representations: ASR for speech-to-text, NLP pipelines for text normalization and intent detection, and vision models (CNNs, Vision Transformers, OCR) for images and video frames. Use modality-specific pre- and post-processing: noise reduction for audio, codec-aware resizing for images, and tokenization for text.
Representation and fusion
Fusion approaches range from early fusion (concatenating modality embeddings) to late fusion (separate pipelines combined at decision time) and cross-attention fusion inside multimodal encoders. Cross-attention and multimodal transformers are common in 2025 for tight integration between modalities; retrieval-augmented generation is used when external knowledge is required.
Central reasoning and policy layer
The reasoning layer often uses a large language model (LLM) or multimodal model that interprets fused embeddings, generates responses, and issues actions. Policy components control task flow, manage external tool calls, and enforce safety checks (moderation, permission checks). RLHF or constrained fine-tuning can be used to align outputs with intended behavior.
Execution and connectors
Connectors translate agent decisions into real-world actions: databases, home automation APIs, or UI updates. Observability and retry policies are essential to avoid unpredictable end-user interactions.
Data, training, and evaluation
Data strategy and labeling
Collect modality-balanced datasets with aligned annotations where possible (speech transcripts paired with video frames and text). Use active learning to prioritize human review of edge cases. Data augmentation—simulated noise on audio, synthetic images, text paraphrasing—improves robustness.
Evaluation metrics and benchmarks
Evaluation should include modality-specific metrics (WER for ASR, mAP for vision), cross-modal consistency checks, usability measures (task completion, latency), and alignment metrics (safety and hallucination rates). Public benchmarks and enterprise test suites both matter; align with standards from research and organizations such as NIST for risk management practices (NIST AI Risk Management).
MAVIS checklist: A named framework for project readiness
The MAVIS checklist is a practical readiness model to validate multimodal agent projects.
- Modality: Are required modalities supported and quality-tested? (ASR, TTS, OCR, object detection)
- Architecture: Is fusion approach defined and scalable? (early/late/cross-attention)
- Validation: Are evaluation metrics, human review pipelines, and continuous monitoring in place?
- Integration: Are connectors, latency budgets, and fallback behaviors implemented?
- Safety: Are guardrails, access controls, and incident procedures verified?
Practical example: Voice-enabled image-shopping assistant
Scenario: A mobile assistant accepts a photographed item plus a voice request (“Find the nearest store that has this sneaker in size 9”). The flow:
- Camera uploads an image; vision model extracts product features and text via OCR.
- ASR converts speech to text; NLU extracts intent and constraints (size, location).
- Multimodal fusion produces a structured query; the agent calls catalog search APIs and a mapping service.
- Agent responds via synthesized speech with results and an interactive card showing images and store links.
This scenario highlights latency targets for each step, the need for privacy controls for photos, and visible fallback options when recognition is uncertain.
Practical tips for building multimodal AI agents
- Design for graceful degradation: provide clear fallbacks when a modality fails (e.g., ask clarifying questions if ASR confidence is low).
- Benchmark latency per component; set tight budgets for perception pipelines and use streaming inference where possible.
- Instrument end-to-end telemetry: track modality confidence, fusion activations, and downstream task success to detect regressions.
- Use modular connectors with schema contracts so tools and services can be swapped without changing the core agent.
Trade-offs and common mistakes
Trade-offs
Strong fusion (tight integration) improves contextual understanding but increases compute and latency. Late fusion reduces compute but can miss cross-modal cues. On-device inference improves privacy and latency but limits model size and capability.
Common mistakes
- Overfitting on aligned multimodal datasets that don't match production distributions.
- Neglecting mismatch between human expectations and agent behavior—especially around hallucination and confidence reporting.
- Skipping continuous monitoring and human-in-the-loop review for safety-critical interactions.
Core cluster questions
- How should data be collected and labeled for multimodal training?
- What fusion techniques work best for real-time multimodal agents?
- How to measure and reduce hallucinations in multimodal outputs?
- When to use on-device inference versus cloud-based models for voice and vision?
- How to design safety and privacy controls for image and audio inputs?
Implementation checklist (short)
- Define modalities, datasets, and quality targets.
- Choose fusion approach and model candidates; prototype with a smallest viable pipeline.
- Implement connectors, observability, and rollback procedures.
- Create a human review and feedback loop for edge-case handling and safety tuning.
Monitoring, compliance, and deployment
Deploy with staged rollouts, A/B tests, and monitoring of modality confidence, latency, and user satisfaction. Align risk-management controls to organizational standards; reference public frameworks such as the NIST AI Risk Management Framework for governance guidance.
Conclusion
Building multimodal AI agents in 2025 requires balancing model capability, latency, privacy, and safety. Use structured checklists like MAVIS, instrument end-to-end telemetry, and iterate with human reviews. Proper fusion design and clear fallback strategies turn multimodal research into reliable user experiences.
FAQ
What are multimodal AI agents and how are they built?
Multimodal AI agents process and act on multiple input types—commonly voice, text and vision—by combining modality-specific perception modules, a fusion and reasoning layer, and execution connectors. Building them involves collecting aligned data, choosing fusion strategies, validating with modality-specific and cross-modal metrics, and implementing safety and monitoring.
How is voice, text and vision AI integrated in a single system?
Integration typically uses modality encoders that produce embeddings, which are fused using concatenation, attention-based cross-modal layers, or late decision fusion. A central policy or multimodal model then generates responses or actions that are executed through connectors.
What are the common evaluation metrics for multimodal systems?
Use modality metrics like WER for ASR and mAP for object detection, plus cross-modal metrics for consistency and task success rates. Track latency, user satisfaction, and safety incident rates as operational metrics.
How to reduce hallucinations in multimodal agents?
Use retrieval-augmented generation, grounding sources, calibrate model confidence, tune with human feedback, and implement conservative fallback behaviors when certainty is low.
What governance or standards should teams follow when building these agents?
Follow organizational risk-management processes and public best practices such as the NIST AI Risk Management Framework for governance, documentation, and validation procedures.