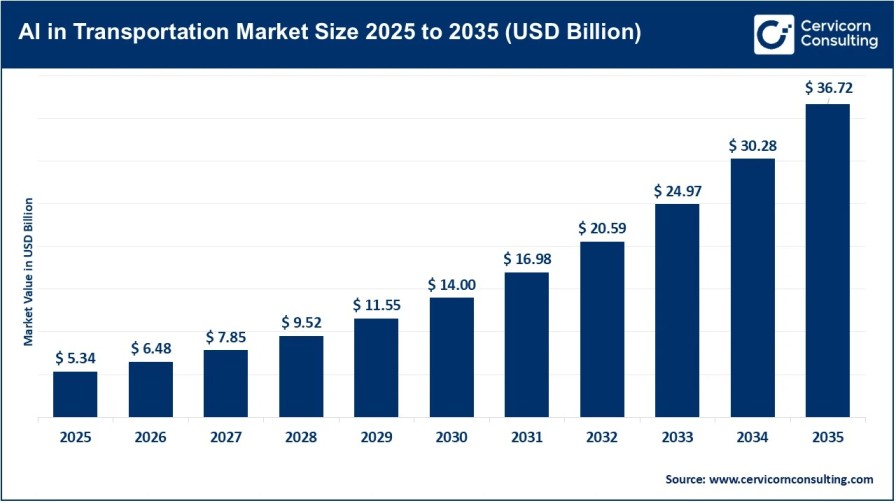
Practical Guide to Integrating Machine Learning and AI into Cloud Analytics
-

- February 23rd, 2026
- 1,317 views

FREE SEO Topical Map Generator: Find Your Next Content Ideas
Integrating AI and machine learning in cloud analytics helps organizations extract real-time insights, scale model training, and operationalize predictions across applications. This article explains common architectures, data and model lifecycle patterns, governance considerations, and operational practices for reliable cloud analytics powered by AI and machine learning.
- Design data pipelines that separate feature engineering, model training, and serving for scalability.
- Adopt MLOps practices for continuous integration, deployment, and monitoring of models.
- Address security, privacy, and governance using standards and regulator guidance.
- Balance batch and real-time analytics to meet latency and cost requirements.
AI and machine learning in cloud analytics: core concepts and architecture
Architectures for cloud analytics with embedded AI typically separate storage, compute, and model serving. Data lakes or data warehouses store raw and processed datasets; distributed compute clusters or managed services handle feature extraction and model training; and low-latency prediction endpoints serve models to applications. Designing for loose coupling between these layers enables independent scaling and clearer operational boundaries.
Key architectural patterns
Common patterns include:
- Batch analytics pipeline: periodic ETL, offline model training, and scheduled bulk scoring for reporting and BI.
- Streaming analytics pipeline: real-time feature computation and model inference for event-driven decisions.
- Hybrid pipelines: combine batch and stream processing with feature stores to serve both training and serving needs.
Data management and pipelines
Data ingestion and storage
Reliable ingestion supports a mix of structured and unstructured sources. Proven practices include immutable event logs, schema versioning, and metadata catalogs. Tagging data lineage and provenance aids traceability for audits and debugging.
Feature engineering and feature stores
Feature stores centralize computed features for reuse across training and serving to reduce drift and duplication. Version control for feature definitions and automated validation checks improve reproducibility.
Model lifecycle and MLOps
Training, validation, and versioning
Automated pipelines for training and validation help enforce quality gates before deployment. Keep artifacts, hyperparameters, and datasets versioned in model registries. Reproducible experiments accelerate root-cause analysis when performance changes.
Continuous deployment and rollback
Blue/green or canary deployments reduce risk when promoting models to production. Automated rollback procedures based on monitoring signals (such as accuracy or latency thresholds) are essential to maintain service quality.
Security, privacy, and governance
Regulatory and standards guidance
Compliance often involves data protection regulations and algorithmic transparency requirements. Organizations should map applicable laws and standards (for example, data protection frameworks and ISO security standards), and consider guidance from regulatory bodies and technical organizations such as NIST when developing governance programs.
Privacy-preserving techniques
Privacy-preserving methods include data minimization, anonymization, differential privacy, and federated learning for decentralized model training. Risk assessments and regular audits help identify potential privacy leakage from models and data pipelines.
Operational considerations: performance, cost, and monitoring
Performance and scaling
Match compute resources to workload patterns: burstable instances or auto-scaling clusters for training peaks, and optimized low-latency instances or edge inference for real-time serving. Profiling model inference and optimizing serialization and batching reduce latency and cost.
Monitoring and observability
Monitor data input distributions, feature drift, model performance metrics, and infrastructure signals. Alerting on significant drift or degraded accuracy enables timely model retraining or rollback. Logging and distributed tracing assist incident investigation.
Deployment patterns and integration
Embedding predictions into analytics
Predictions can be stored alongside analytic results to support downstream BI, dashboards, or automated decisioning. Ensure prediction metadata (model version, confidence, timestamp) is stored to maintain context for audits and analysis.
APIs and event-driven integrations
Well-defined inference APIs and event-driven architectures allow applications to request real-time predictions or subscribe to scored events. Secure, rate-limited endpoints with authentication and logging protect services from misuse.
Risk management and ethics
Bias, explainability, and human oversight
Routine bias assessments and tools for explainability help surface unintended model behaviors. Establishing escalation paths and human-in-the-loop review for high-risk decisions supports ethical deployment of AI systems.
Testing and validation
Robust testing should include unit tests for feature logic, integration tests for pipelines, and scenario testing for uncommon edge cases. Simulation of production-like traffic can reveal scalability or latency issues before launch.
Frequently asked questions
What are the benefits of AI and machine learning in cloud analytics?
AI and machine learning in cloud analytics enable automated pattern detection, predictive insights, personalization, and operational automation. Cloud platforms provide scalable compute and storage to accelerate experimentation and production deployment while supporting near real-time inference at scale.
How should data governance be applied to cloud-based ML pipelines?
Apply classification, access controls, and provenance tracking across datasets. Maintain catalogs and lineage metadata, enforce encryption in transit and at rest, and document data retention and deletion policies aligned with regulatory requirements.
When is real-time inference preferred over batch scoring?
Real-time inference is preferred when decisions must be made within strict latency windows (for example, fraud detection or personalized user experiences). Batch scoring suits periodic reporting, model retraining labels, and scenarios where immediate response is unnecessary.