How to Choose and Use a Data Cleaning Tool for Messy, Inconsistent Datasets
-

- March 28th, 2026
- 175 views


FREE SEO Topical Map Generator: Find Your Next Content Ideas
Cleaning messy input is a routine requirement before analysis or production systems can use data. Choosing a reliable data cleaning tool starts with clear goals: remove duplicates, standardize formats, fix missing or conflicting values, and retain traceability of changes. This guide explains how to evaluate and use a data cleaning tool for messy and inconsistent dataset preparation, with a checklist, example workflow, and practical tips.
- Identify the exact data quality problems (duplicates, format variance, nulls, outliers).
- Match tool capabilities to scale, repeatability, and traceability needs.
- Follow the CLEANER checklist for a repeatable process.
- Use automation where possible but keep human review steps for edge cases.
Choosing a data cleaning tool: core capabilities to compare
Select a tool based on the dataset size, source variety, and whether cleaning must be repeated automatically. A good data cleaning tool should provide profiling (data summaries and error counts), transformation primitives (type conversions, normalization), deduplication, pattern-based corrections (regular expressions or rules), and auditing (logs or change histories).
Key capabilities and trade-offs
- Profiling: Fast column-level summaries reveal null rates, unique counts, and value distributions.
- Transformation power: GUI mapping helps non-coders; scripting (Python, SQL) enables complex rules.
- Scale and performance: In-memory tools are quick for small data; distributed engines are required for large volumes.
- Traceability: Auditable change logs or exportable scripts are essential for reproducibility and compliance (see ISO data quality principles).
Common mistakes when selecting a tool
- Picking a tool based on UI alone without checking automation and export options.
- Ignoring how the tool logs transformations, which complicates debugging later.
- Assuming one tool fits all data sizes—proof a tool on representative data first.
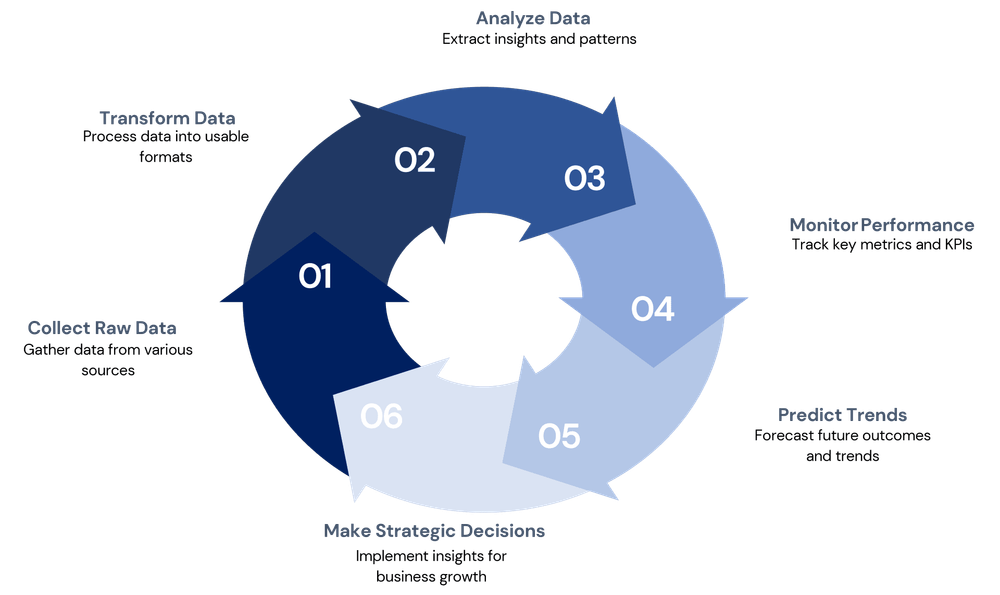
Practical process: the CLEANER checklist for dataset preparation
Use the CLEANER checklist as a repeatable framework before running production steps.
- Catalog sources: record schema, source owner, and update frequency.
- Look for patterns: run profiling to list nulls, distinct counts, and common formats.
- Evaluate impact: decide which issues block downstream use (e.g., missing IDs).
- Apply deterministic rules: standardize dates, numeric formats, and text case.
- Normalize values: create lookup tables for canonical values (countries, product codes).
- Execute deduplication: rule-based or probabilistic matching to remove duplicates.
- Review and log: save a transformation script or audit file for traceability.
Real-world example: cleaning a customer import
Scenario: Monthly CSV imports from several regional CRMs feed a central customer database. Incoming files have inconsistent date formats, duplicated customer records with minor name variations, and missing country codes.
Applied steps: run a profiler to detect date formats, standardize all dates to ISO 8601, use a fuzzy-match deduplication step on name+email+phone with manual review for near matches, and map country names to ISO codes via a lookup table. Produce an automated script from the tool so the same steps run on the next import.
Automation and workflows
Automated data cleansing workflows reduce manual labor but require robust error handling and monitoring. For repeated imports, export transformations as scripts or API-based processes so the pipeline can run in a scheduled job. For code-based approaches, libraries like the Pandas documentation offer best-practice patterns for reproducible transformations.
When to automate vs. manual review
- Automate deterministic fixes (format normalization, null imputation with clear rules).
- Keep manual review for ambiguous records (conflicting values, high-impact customers) and record those decisions.
Practical tips for cleaner datasets
- Always profile before changing data to quantify the problem and measure improvement.
- Version transformations: store scripts or exported recipes alongside the cleaned output for reproducibility.
- Prefer rule-based normalization plus targeted ML matching for fuzzy deduplication when scale permits.
- Log all automatic corrections with counts and example rows so reviewers can audit changes quickly.
Trade-offs and common mistakes
Choosing between GUI tools and scripting is a trade-off: GUIs are faster for one-off projects and accessible to non-coders, while scripts are better for complex logic and automated pipelines. Over-cleaning—aggressive imputation or normalization—can remove valid variability and introduce bias. Failing to keep an audit trail makes it hard to justify decisions or revert changes when errors surface.
FAQ
What is a data cleaning tool and why is it necessary?
A data cleaning tool is software that detects and corrects errors, inconsistencies, and missing values in datasets so downstream processes can rely on accurate, consistent inputs. It is necessary because messy data causes incorrect analyses, failed integrations, and poor model performance.
How to choose the best data cleaning tool for a specific workflow?
Match the tool to the primary constraints: dataset size, frequency (one-off vs recurring), need for auditability, and user skill set. Test candidate tools on a representative sample and check for repeatable exportable transformations.
What are the core steps in dataset preparation for inconsistent data?
Profile the data, catalog issues, apply deterministic normalization rules, deduplicate, and validate results against known constraints. Use the CLEANER checklist to structure the process.
Can automated data cleansing workflows handle complex deduplication?
Yes, automated workflows can combine deterministic keys with probabilistic or ML-based fuzzy matching. Include manual review for edge cases and keep thresholds conservative to avoid false merges.
Is a GUI tool or scripting better for dirty data remediation tools?
GUI tools accelerate ad hoc cleaning and make mapping easier for non-technical users. Scripting (Python, SQL) gives full control, versioning, and better automation for production pipelines. Choose based on repeatability and team skills.
Further reading: consult official library and platform documentation for recommended patterns and APIs; many production teams follow standards from data governance frameworks and ISO data quality principles to ensure consistency and traceability.