Stable Diffusion Image Generation: Practical Guide, Prompts, and Best Practices
-

- March 25th, 2026
- 209 views


FREE SEO Topical Map Generator: Find Your Next Content Ideas
Stable Diffusion image generation produces detailed images by reversing a noise process inside a learned latent space. This guide explains the key concepts, practical workflow, and concrete settings that produce reliable outputs without guessing—covering prompt structure, sampling parameters, model checkpoints, and common pitfalls.
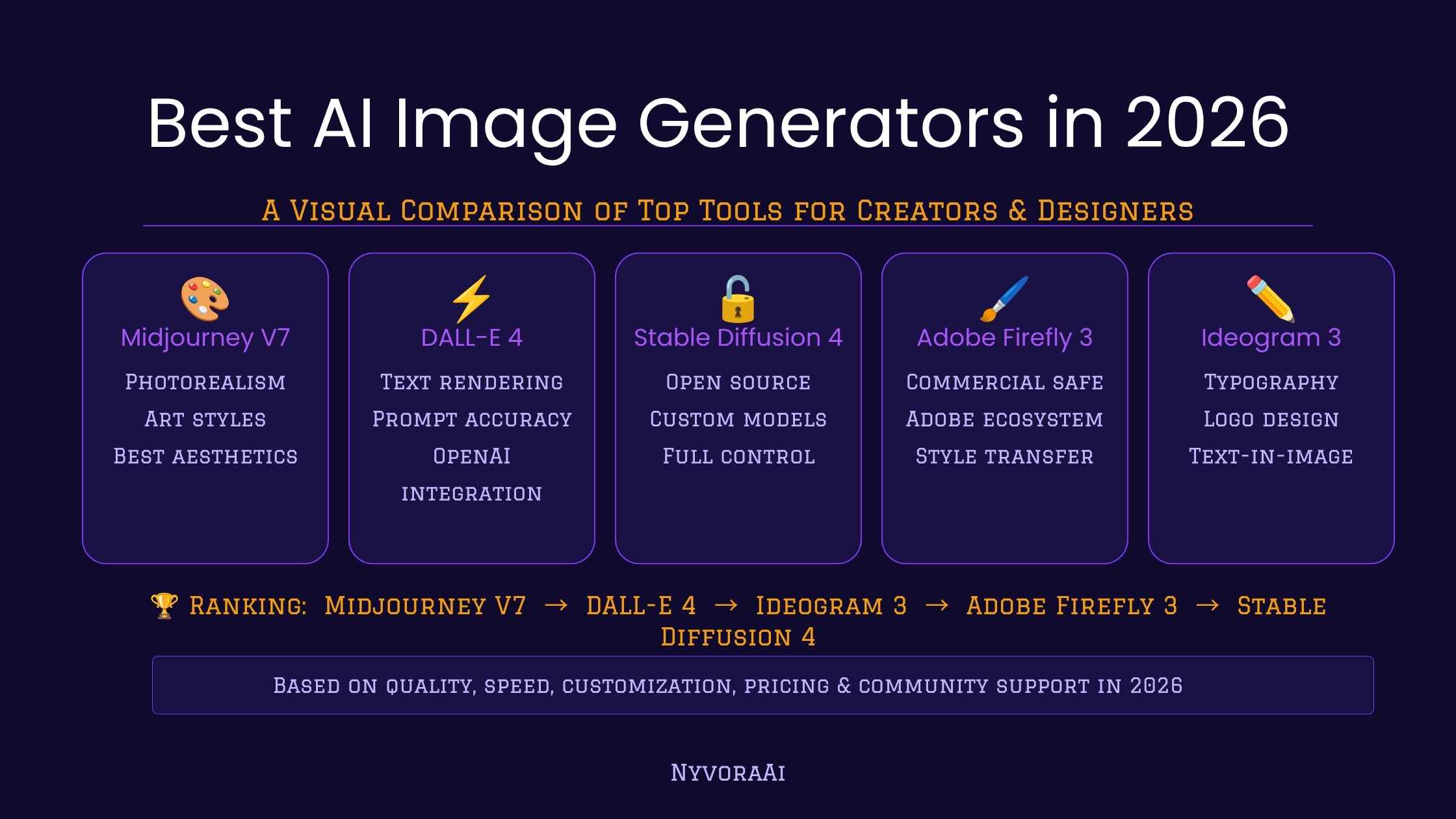
- Stable Diffusion is a latent diffusion model that turns text prompts into images using a diffusion denoising process.
- Follow a simple 3-step G.E.N. Checklist: Generate → Evaluate → Narrow (refine prompts or settings).
- Use practical settings: 25–50 steps, guidance scale 6–8.5, deterministic sampler for repeatability, and a fixed seed for reproducible results.
Stable Diffusion image generation: how it works
Stable Diffusion is built on the latent diffusion model architecture: a noisy latent vector is iteratively denoised by a neural network (UNet) guided by a text encoder, typically CLIP or similar. The process happens in a lower-dimensional latent space to reduce compute cost while preserving visual fidelity. Related terms and entities include diffusion model, latent space, guidance scale, sampler, seed, checkpoints, fine-tuning methods such as LoRA and DreamBooth, and hosting platforms like Hugging Face and model providers such as Stability AI (stability.ai).
Core components and jargon
- Text encoder: converts prompts into embeddings used to guide the denoiser (CLIP is common).
- UNet denoiser: the neural network that removes noise step-by-step.
- Latent space: compressed representation where diffusion happens.
- Guidance scale: balances adherence to the prompt vs. diversity (higher = more faithful to prompt).
- Sampler: algorithm that steps through diffusion (Euler, DDIM, PLMS, etc.).
Practical workflow and the 3-step G.E.N. Checklist
Use a repeatable workflow to reduce variance and speed iteration. The named framework below structures prompt experiments and parameter tweaks.
3-step G.E.N. Checklist (Generate–Evaluate–Narrow)
- Generate: Run a baseline with conservative settings (30 steps, guidance scale 7.5, deterministic sampler) and a clear prompt.
- Evaluate: Inspect composition, subject clarity, and artifacts. Note what failed: composition, facial detail, or color palette.
- Narrow: Adjust one variable at a time: modify prompt tokens, change guidance scale by ±1.0, alter steps by ±10, or try a different sampler.
Repeatability and version control
Record model checkpoint, seed, sampler, steps, guidance scale, and any fine-tuning or LoRA used. This produces reproducible results and faster debugging.
Prompt engineering, parameters, and a real-world example
Prompt structure and common modifiers
Start with a concise subject, add artistic style and medium, then technical modifiers. Examples of modifiers: "high detail", "cinematic lighting", "8k", "photorealistic", "digital painting", "soft shadows", "bokeh". Avoid contradictory modifiers (e.g., "cartoon" and "photorealistic").
Real-world scenario: book cover for a fantasy novel
Goal: Generate a moody fantasy book cover with a lone castle on a cliff at dusk. Baseline prompt: "lonely medieval castle on a cliff at dusk, dramatic clouds, cinematic lighting, detailed stone texture, atmospheric perspective, digital painting, 2:3 aspect ratio" Settings: steps 40, guidance scale 7.5, sampler Euler a, seed 123456, use a 2:3 aspect ratio for vertical cover. If faces or text overlay are required, add negative prompts such as "blurry text, watermark" and refine composition with additional tokens like "foreground silhouette" or use inpainting for adding title text later.
Practical tips for reliable outputs
- Fix a seed for reproducibility when testing prompt variations; change it intentionally to explore diversity.
- Use moderate guidance scale first (6–8). Increase if the subject drifts from the prompt; decrease if results become rigid or overfitted.
- Raise steps gradually: 20–30 for quick previews, 30–60 for final renders. Diminishing returns appear past ~60 steps for many samplers.
- Prefer explicit descriptive nouns and adjectives over vague terms. Instead of "nice landscape," use "mist-covered pine forest at sunrise."
- When fine details are required (faces, logos), consider a two-pass approach: generate a high-level composition, then use inpainting or fine-tuned checkpoints (e.g., DreamBooth or LoRA) for specifics.
Common mistakes and trade-offs
Trade-offs are unavoidable: higher guidance improves prompt fidelity but reduces diversity and can amplify artifacts. More steps increase quality until computational cost and over-smoothing become issues. Samplers trade speed versus quality—DDIM and Euler a are common choices with different behavior. Common mistakes include:
- Changing multiple parameters at once—hindering diagnosis of what caused improvement or regression.
- Overloading prompts with many contradictory style tags; this confuses the text encoder.
- Ignoring model checkpoint differences—different checkpoints have different aesthetic biases and token behaviors.
Hardware, fine-tuning, and deployment notes
Local generation typically requires a GPU with sufficient VRAM (6–12+ GB for smaller images; 16+ GB for high-res or larger batch sizes). For large-scale or production use, consider cloud GPUs and model-serving solutions. Fine-tuning options range from full checkpoint training to lighter-weight approaches like LoRA and DreamBooth for custom subjects. Always test custom models on representative prompts before deploying.
Practical considerations for compliance and licensing
Check model license and the source of any training data when using outputs commercially. Keep records of model versions and any third-party assets used in composite images.
FAQ
What is Stable Diffusion image generation?
Stable Diffusion image generation uses a latent diffusion process guided by text embeddings to convert text prompts into images. The model iteratively denoises a latent vector to produce a final image, balancing prompt fidelity and visual diversity through parameters like guidance scale and sampling steps.
How can prompt engineering improve results?
Prompt engineering clarifies the subject, style, composition, and technical details. Use direct nouns and descriptive adjectives, include medium and lighting terms, and apply negative prompts to remove unwanted elements. Iterate using the G.E.N. checklist to refine prompts methodically.
What hardware is required to run Stable Diffusion locally?
A GPU with at least 6–8 GB VRAM can run smaller resolutions; 12–16+ GB is recommended for higher resolutions or batch processing. CPU-only execution is possible but very slow. For production, use dedicated GPUs or cloud services.
How to fine-tune a model for a custom style?
Fine-tuning options include full checkpoint training, DreamBooth for subject-specific adaptation, and LoRA for lightweight style transfer. Choose based on available data, compute, and whether the goal is a full model change or a small, reusable adapter.
Are there ethical or legal issues when using these images?
Yes. Review licenses for model checkpoints and training datasets, avoid infringing on copyrighted characters or trademarks, and follow platform terms for content that may involve privacy, deepfakes, or sensitive subjects.