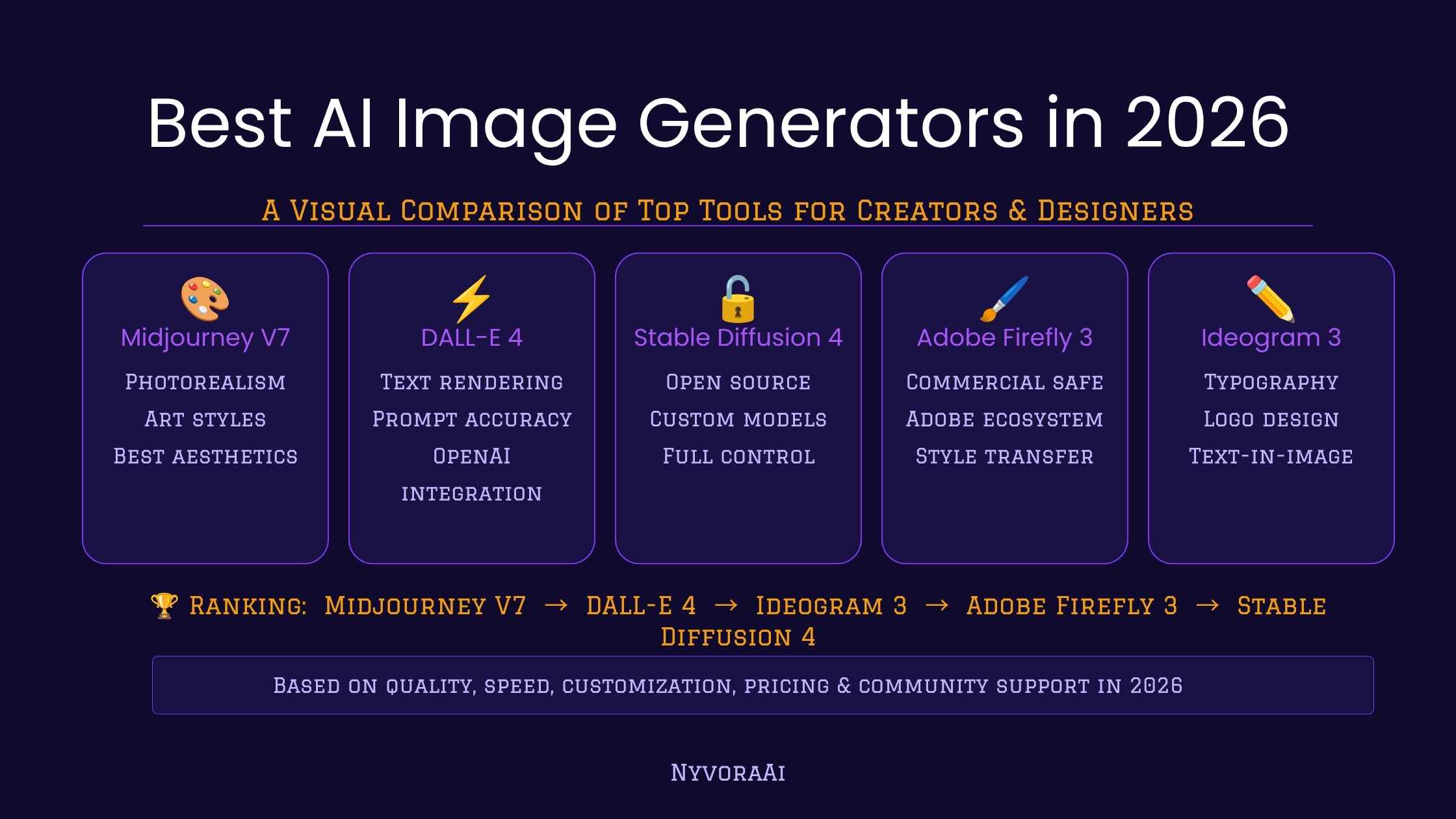
Fine-Tune Stable Diffusion with LoRA: Practical Steps, Checklist, and Tips
-

- March 30th, 2026
- 260 views


FREE SEO Topical Map Generator: Find Your Next Content Ideas
Introduction
Stable Diffusion LoRA fine-tuning adapts a base diffusion model using low-rank adapters that modify a subset of weights instead of retraining the whole network. This method reduces compute, storage, and risk of overfitting while enabling targeted style, subject, or domain adaptation.
- LoRA trains small low-rank weight matrices (adapters) that plug into the U-Net or attention blocks.
- Requires far fewer parameters and GPU hours than full fine-tuning.
- Follow a checklist for dataset prep, hyperparameters, and validation to avoid common mistakes.
Stable Diffusion LoRA fine-tuning: When and How to Use It
LoRA adapters for Stable Diffusion are best when the goal is targeted adaptation—adding a new art style, improving subject fidelity, or correcting a domain gap—without creating a new full checkpoint. LoRA is compatible with training frameworks that expose U-Net or attention weights and is widely used because of its efficiency and modularity.
How LoRA works and key terms
Low-Rank Adaptation (LoRA)
LoRA injects low-rank matrices into selected weight layers, learning delta updates while freezing the original parameters. Core terms: rank (r), alpha (scaling), adapters, merged checkpoint, and inference merge.
Related model components
Terms to know: U-Net, attention QKV matrices, text encoder/CLIP embeddings, denoising steps, scheduler (DDIM/PLMS/DPMSolver), and guidance scale (classifier-free guidance).
Practical step-by-step workflow
1) Prepare data and labels
Collect 50–1000 images depending on task complexity. Clean images to consistent size (512×512 common), split into training/validation, and prepare captions that capture desired attributes. For subject-specific fine-tuning, include multiple poses and backgrounds.
2) Choose layers and rank
Select attention or MLP layers in the U-Net for adapter insertion. Typical ranks range from 4 to 32; lower ranks for subtle style changes, higher ranks for stronger adaptation.
3) Configure training
Use AdamW or Adam with weight decay, small learning rates (1e-4 to 1e-5 effective for adapter params), gradient accumulation if batch size is constrained, and mixed precision (fp16) to save memory.
4) Train and monitor
Track training and validation loss and sample outputs every N checkpoints. Save adapter files periodically and keep a merged checkpoint for final evaluation.
The LORA-FINE checklist (named checklist)
- L: Label & clean dataset (consistent size, clear captions)
- O: Obtain base model checksum and confirm architecture
- R: Rank selection (start small: r=8)
- A: Adapter insertion points documented (layers and modules)
- F: Fine-tune hyperparameters saved (lr, batch, steps)
- I: Inference test plan (samples, prompts, guidance scale)
- N: Numeric validation (FID/CLIP score where feasible)
- E: Export adapters with metadata (prompts, training date)
Real-world scenario
An illustrator needs a signature watercolor look for commissioned portraits. Using 300 curated and captioned portrait photos, adapters were inserted in attention blocks with rank=16, trained for 2,000 steps with lr=5e-5 on fp16. Validation samples were reviewed after every 250 steps and the final adapter produced consistent color blending and brush-like textures without altering face structure.
Practical tips
- Start with small rank and low learning rate; increase only if the model fails to capture the target effect.
- Use mixed-precision training to reduce GPU memory and increase batch sizes—this improves stability for adapter training.
- Keep a validation set and evaluate both visual diversity and attribute accuracy; monitor for mode collapse.
- Document prompt templates and negative prompts used during evaluation so results are reproducible.
- Store adapter metadata (base model, layer list, rank, hyperparameters) with the adapter file for future compatibility.
Trade-offs and common mistakes
Trade-offs
LoRA adapters are lightweight and faster to train, but may not capture extreme domain shifts that require full-model updates. Adapters can be merged for inference, but merged checkpoints increase storage if many variants are produced. Rank selection balances capacity versus overfitting and compute.
Common mistakes
- Using inconsistent image sizes—causes artifacts during denoising.
- Training with too high a learning rate—produces unstable or broken outputs.
- Skipping validation—overfitting often goes unnoticed without held-out samples.
- Not freezing the correct parameters—verify only adapter parameters are updated if that is the intent.
Resources and best-practice reference
For implementation details and API examples in popular libraries, review the official guide on LoRA for diffusion models: Hugging Face LoRA guide.
Validation and deployment
Evaluation metrics
Use qualitative sampling and, where possible, objective metrics such as CLIP score, FID, or perceptual similarity. Compare generated samples using the same seed and prompt templates to isolate the adapter effect.
Deployment considerations
During inference, load the base model and apply the adapter with merge or dynamic injection. Keep adapter files small and include versioning to prevent mismatches with future base model updates.
FAQ
What is Stable Diffusion LoRA fine-tuning and when should it be used?
Stable Diffusion LoRA fine-tuning adapts a base diffusion model by training small low-rank adapters to change behavior for a specific style, subject, or domain. Use it when efficiency and modularity are priorities and full model retraining is unnecessary.
How many images are needed for LoRA adapters?
Data needs vary. For style tweaks, 50–200 images may be enough. For subject-specific fidelity, 200–1000 diverse images yield better results. Always set aside a validation set.
Can LoRA adapters be merged into a full checkpoint?
Yes. Adapters can be merged into a full checkpoint for standalone inference. Keep a record of adapter metadata before merging to preserve reproducibility.
Which hyperparameters most affect low-rank adaptation training?
Rank, learning rate, weight decay, batch size, and number of training steps are the most influential. Start conservative and adjust based on validation samples.
How to apply a trained LoRA adapter during inference?
Load the base Stable Diffusion model, load the LoRA adapter for the corresponding layers, and run the usual sampling pipeline with the chosen guidance scale. Ensure base model and adapter compatibility before inference.
Are there licensing or safety considerations?
Confirm compliance with the base model license and applicable laws for generated content. Evaluate outputs for safety and potential copyright or trademark issues before commercial use.