 Guaranteed SEO Boost: Triple Your Rankings with Backlinks starting at 5$
Guaranteed SEO Boost: Triple Your Rankings with Backlinks starting at 5$
Written by TeachAhead » Updated on: November 13th, 2024

 Data powers AI systems, enabling them to generate insights, predict outcomes, and transform decision-making. However, AI’s impact hinges on the quality and readiness of the data it consumes. A recent Harvard Business Review report reveals a troubling trend: approximately 80% of AI projects fail, largely due to poor data quality, irrelevant data, and a lack of understanding of AI-specific data requirements.
Data powers AI systems, enabling them to generate insights, predict outcomes, and transform decision-making. However, AI’s impact hinges on the quality and readiness of the data it consumes. A recent Harvard Business Review report reveals a troubling trend: approximately 80% of AI projects fail, largely due to poor data quality, irrelevant data, and a lack of understanding of AI-specific data requirements.
As AI technologies are projected to contribute up to $15.7 trillion to the global economy by 2030, the emphasis on AI-ready data is more urgent than ever. Investing in data readiness is not merely technical; it’s a strategic priority that shapes AI’s effectiveness and a company’s competitive edge in today’s data-driven landscape.
With advancements in generative AI in 2023, automation in data processing and data collection can be moderately increased. While both areas already had significant automation potential, data processing, in particular, can now reach over 90% automation with generative AI.
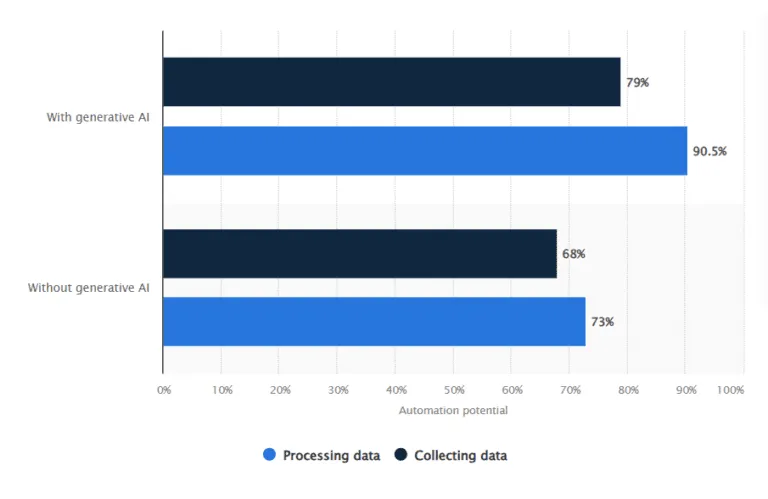
(Source: Statista)
Achieving AI-ready data requires addressing identified gaps by building strong data management practices, prioritizing data quality enhancements, and using technology to streamline integration and processing. By proactively tackling these issues, organizations can significantly improve data readiness, minimize AI project risks, and unlock AI’s full potential to fuel innovation and growth.
In this article, we’ll explore what constitutes AI-ready data and why it is vital for effective AI deployment. We will also examine the primary obstacles to data readiness, the characteristics that define AI-ready data, and the practices for data preparation. Furthermore, well discuss how to align data with specific use-case requirements. By understanding these elements, businesses can ensure their data is not only AI-ready but optimized to deliver substantial value.
Key Takeaways:
What is AI-Ready Data?
AI-ready data refers to data that is meticulously prepared, organized, and structured for optimized use in artificial intelligence applications. This concept goes beyond simply accumulating large data volumes; it demands data that is accurate, relevant, and formatted specifically for AI processes. With AI-ready data, every element is curated for compatibility with AI algorithms, ensuring data can be swiftly analyzed and interpreted.
For data to be considered AI-ready, it must meet specific criteria:
 High quality: AI-ready data is accurate, complete, and free from inconsistencies. These factors ensure that AI algorithms function without bias or error.
High quality: AI-ready data is accurate, complete, and free from inconsistencies. These factors ensure that AI algorithms function without bias or error.
In essence, AI-ready data isn’t abundant, it’s purposefully refined to empower AI-driven solutions and insights.
Key Characteristics of AI-Ready Data
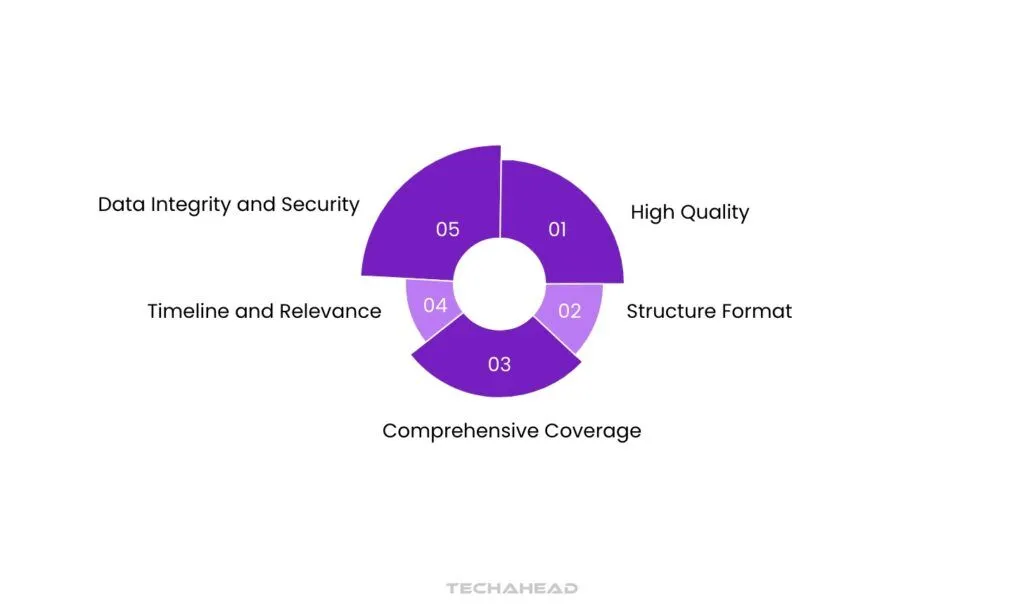 High Quality
High Quality
For data to be truly AI-ready, it must demonstrate high quality across all metrics—accuracy, consistency, and reliability. High-quality data minimizes risks, such as incorrect insights or inaccurate predictions, by removing errors and redundancies. When data is meticulously validated and free from inconsistencies, AI models can perform without the setbacks caused by “noisy” or flawed data. This ensures AI algorithms work with precise inputs, producing trustworthy results that bolster strategic decision-making.
Structure Format
While AI systems can process unstructured data (e.g., text, images, videos), structured data vastly improves processing speed and accuracy. Organized in databases or tables, structured data is easier to search, query, and analyze, significantly reducing the computational burden on AI systems. With AI-ready data in structured form, models can perform complex operations and deliver insights faster, supporting agile and efficient AI applications. For instance, structured financial or operational data enables rapid trend analysis, fueling responsive decision-making processes.
Comprehensive Coverage
AI-ready data must cover a complete and diverse spectrum of relevant variables. This diversity helps AI algorithms account for different scenarios and real-world complexities, enhancing the model’s ability to make accurate predictions.
For example, an AI model predicting weather patterns would benefit from comprehensive data, including temperature, humidity, wind speed, and historical patterns. With such diversity, the AI model can better understand patterns, make reliable predictions, and adapt to new situations, boosting overall decision quality.
Timeline and Relevance
For data to maintain its AI readiness, it must be current and pertinent to the task. Outdated information can lead AI models to make erroneous predictions or irrelevant decisions, especially in dynamic fields like finance or public health. AI-ready data integrates recent updates and aligns closely with the model’s goals, ensuring that insights are grounded in present-day realities. For instance, AI systems for fraud detection rely on the latest data patterns to identify suspicious activities effectively, leveraging timely insights to stay a step ahead of evolving threats.
Data Integrity and Security
Security and integrity are foundational to trustworthy AI-ready data. Data must remain intact and safe from breaches to preserve its authenticity and reliability. With robust data integrity measures—like encryption, access controls, and validation protocols—AI-ready data can be protected from unauthorized alterations or leaks. This security not only preserves the quality of the AI model but also safeguards sensitive information, ensuring compliance with privacy standards. In healthcare, for instance, AI models analyzing patient data require stringent security to protect patient privacy and trust.
Key Drivers of AI-Ready Data
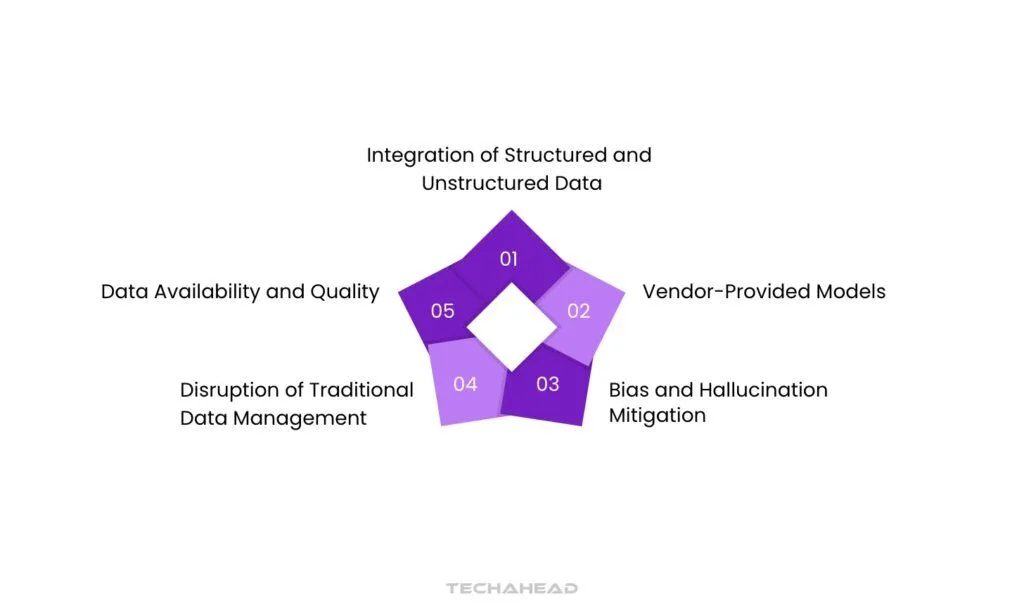 Understanding the drivers behind the demand for AI-ready data is essential. Organizations can harness the power of AI technologies better by focusing on these factors.
Understanding the drivers behind the demand for AI-ready data is essential. Organizations can harness the power of AI technologies better by focusing on these factors.
Vendor-Provided Models
Many AI models, especially in generative AI, come from external vendors. To fully unlock their potential, businesses must optimize their data. Pre-trained models thrive on high-quality, structured data. By aligning their data with these models’ requirements, organizations can maximize results and streamline AI integration. This compatibility ensures that AI-ready data empowers enterprises to achieve impactful outcomes, leveraging vendor expertise effectively.
Data Availability and Quality
Quality data is indispensable for effective AI performance. Many companies overlook data challenges unique to AI, such as bias and inconsistency. To succeed, organizations must ensure that AI-ready data is accurate, representative, and free of bias. Addressing these factors establishes a strong foundation, enabling reliable, trustworthy AI models that perform predictably across use cases.
Disruption of Traditional Data Management
AI’s rapid evolution disrupts conventional data management practices, pushing for dynamic, innovative solutions. Advanced strategies like data fabrics and augmented data management are becoming critical for optimizing AI-ready data. Techniques like knowledge graphs enhance data context, integration, and retrieval, making AI models smarter. This shift reflects a growing need for data management innovations that fuel efficient, AI-driven insights.
Bias and Hallucination Mitigation
New solutions tackle AI-specific challenges, such as bias and hallucination. Effective data management structures and prepares AI-ready data to minimize these issues. By implementing strong data governance and quality control, companies can reduce model inaccuracies and biases. This proactive approach fosters more reliable AI models, ensuring that decisions remain unbiased and data-driven.
Integration of Structured and Unstructured Data
Generative AI blurs the line between structured and unstructured data. Managing diverse data formats is crucial for leveraging generative AI’s potential. Organizations need strategies to handle and merge various data types, from text to video. Effective integration enables AI-ready data to support complex AI functionalities, unlocking powerful insights across multiple formats.
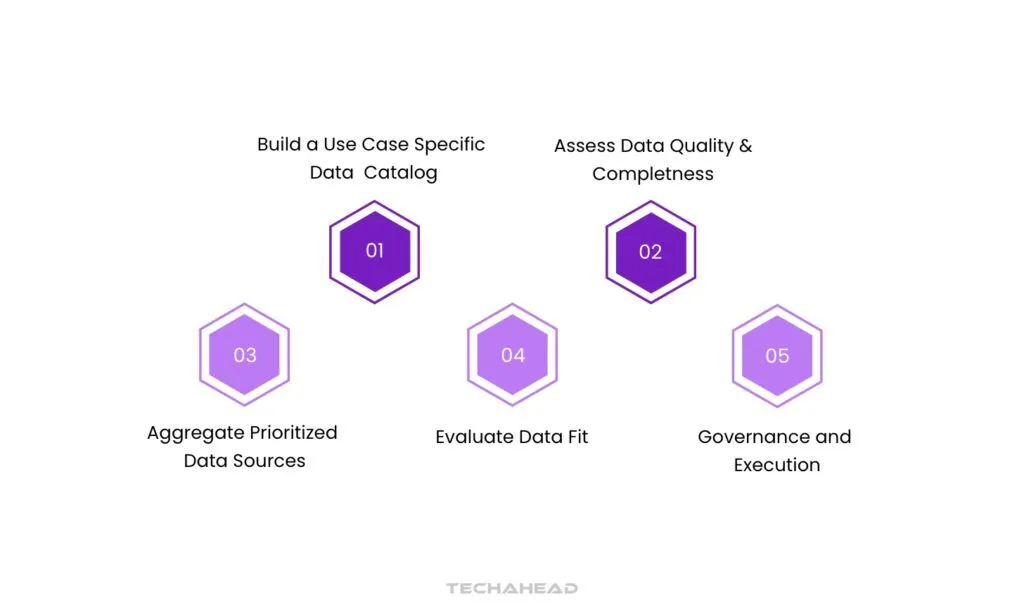
5 Steps to AI-Ready Data
The ideal starting point for public-sector agencies to advance in AI is to establish a mission-focused data strategy. By directing resources to feasible, high-impact use cases, agencies can streamline their focus to fewer datasets. This targeted approach allows them to prioritize impact over perfection, accelerating AI efforts.
While identifying these use cases, agencies should verify the availability of essential data sources. Building familiarity with these sources over time fosters expertise. Proper planning can also support bundling related use cases, maximizing resource efficiency by reducing the time needed to implement use cases. Concentrating efforts on mission-driven, high-impact use cases strengthens AI initiatives, with early wins promoting agency-wide support for further AI advancements.
Following these steps can ensure agencies select the right datasets that meet AI-ready data standards.
Step 1: Build a Use Case Specific Data Catalog
The chief data officer, chief information officer, or data domain owner should identify relevant datasets for prioritized use cases. Collaborating with business leaders, they can pinpoint dataset locations, owners, and access protocols. Tailoring data discovery to agency-specific systems and architectures is essential. Successful data catalog projects often include collaboration with system users and technical experts and leverage automated tools for efficient data discovery.
For instance, one federal agency conducted a digital assessment to identify datasets that drive operational efficiency and cost savings. This process enabled them to build a catalog accessible to data practitioners across the agency.
Step 2: Assess Data Quality and Completeness
AI success depends on high-quality, complete data for prioritized use cases. Agencies should thoroughly audit these sources to confirm their AI-ready data status. One national customs agency did this by selecting priority use cases and auditing related datasets. In the initial phases, they required less than 10% of their available data.
Agencies can adapt AI projects to maximize impact with existing data, refining approaches over time. For instance, a state-level agency improved performance by 1.5 to 1.8 times using available data and predictive analytics. These initial successes paved the way for data-sharing agreements, focusing investment on high-impact data sources.
Step 3: Aggregate Prioritized Data Sources
Selected datasets should be consolidated within a data lake, either existing or purpose-built on a new cloud-based platform. This lake serves analytics staff, business teams, clients, and contractors. For example, one civil engineering organization centralized procurement data from 23 resource planning systems onto a single cloud instance, granting relevant stakeholders streamlined access.
Step 4: Evaluate Data Fit
Agencies must evaluate AI-ready data for each use case based on data quantity, quality, and applicability. Fit-for-purpose data varies depending on specific use case requirements. Highly aggregated data, for example, may lack the granularity needed for individual-level insights but may still support community-level predictions.
Analytics teams can enhance fit by:
A state agency, aiming to support care decisions for vulnerable populations, found their initial datasets incomplete and in poor formats. They improved quality through targeted investments, transforming the data for better model outputs.
Step 5: Governance and Execution
Establishing a governance framework is essential to secure AI-ready data and ensure quality, security, and metadata compliance. This framework doesn’t require exhaustive rules but should include data stewardship, quality standards, and access protocols across environments.
In many cases, existing data storage systems can meet basic security requirements. Agencies should assess additional security needs, adopting control standards such as those from the National Institute of Standards and Technology. For instance, one government agency facing complex security needs for over 150 datasets implemented a strategic data security framework. They simplified the architecture with a use case–level security roadmap and are now executing a long-term plan.
For public-sector success, governance and agile methods like DevOps should be core to AI initiatives. Moving away from traditional development models is crucial, as risk-averse cultures and longstanding policies can slow progress. However, this transition is vital to AI-ready data initiatives, enabling real-time improvements and driving impactful outcomes.
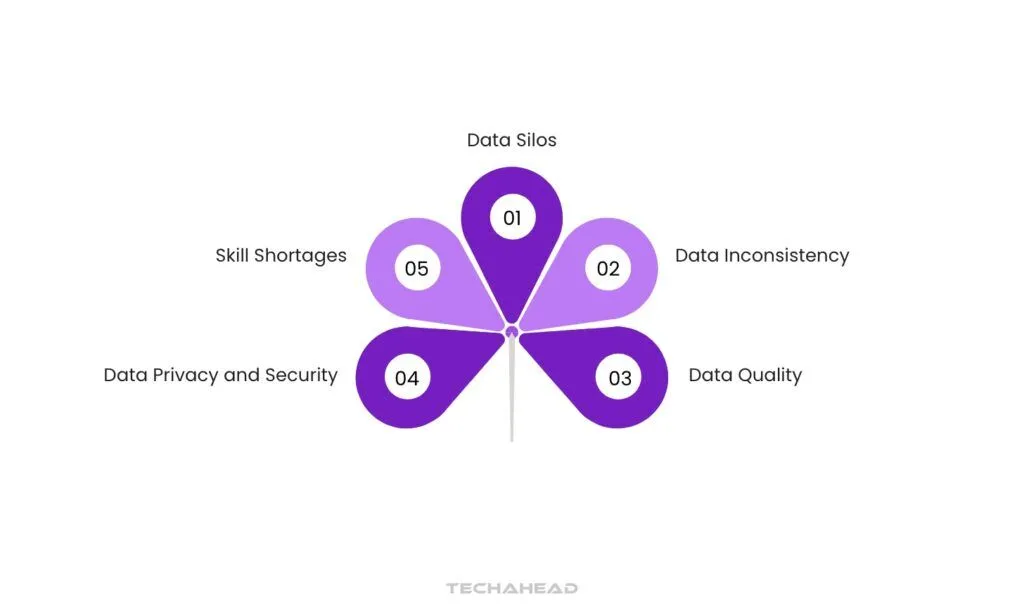
Challenges to AI-Ready Data
 While AI-ready data promises transformative potential, achieving it poses significant challenges. Organizations must recognize and tackle these obstacles to build a strong, reliable data foundation.
While AI-ready data promises transformative potential, achieving it poses significant challenges. Organizations must recognize and tackle these obstacles to build a strong, reliable data foundation.
Data Silos
Data silos arise when departments store data separately, creating isolated information pockets. This fragmentation hinders the accessibility, analysis, and usability essential for AI-ready data.
Impact: AI models thrive on a comprehensive data view to identify patterns and make predictions. Silos restrict data scope, resulting in biased models and unreliable outputs.
Solution: Build a centralized data repository, such as a data lake, to aggregate data from diverse sources. Implement cross-functional data integration to dismantle silos, ensuring AI-ready data flows seamlessly across the organization.
Data Inconsistency
Variations in data formats, terms, and values across sources disrupt AI processing, creating confusion and inefficiencies.
Impact: Inconsistent data introduces errors and biases, compromising AI reliability. For example, a model with inconsistent gender markers like “M” and “Male” may yield flawed insights.
Solution: Establish standardized data formats and definitions. Employ data quality checks and validation protocols to catch inconsistencies. Utilize governance frameworks to uphold consistency across the AI-ready data ecosystem.
Data Quality
Poor data quality—like missing values or errors—undermines the accuracy and reliability of AI models.
Impact: Unreliable data leads to skewed predictions and biased models. For instance, missing income data weakens a model predicting purchasing patterns, impacting its effectiveness.
Solution: Use data cleaning and preprocessing to resolve quality issues. Apply imputation techniques for missing values and data enrichment to fill gaps, reinforcing AI-ready data integrity.
Data Privacy and Security
Ensuring data privacy and security is crucial, especially when managing sensitive information under strict regulations.
Impact: Breaches and privacy lapses damage reputations and erodes trust, while legal penalties strain resources. AI-ready data demands rigorous security to safeguard sensitive information.
Solution: Implement encryption, access controls, and data masking to secure AI-ready data. Adopt privacy-enhancing practices, such as differential privacy and federated learning, for safer model training.
You can read about the pillars of AI security.
Skill Shortages
Developing and maintaining an AI-ready data infrastructure requires specialized skills in data science, engineering, and AI.
Impact: Without skilled professionals, organizations struggle to govern data, manage quality, and design robust AI solutions, stalling progress toward AI readiness.
Solution: Invest in hiring and training for data science and engineering roles. Collaborate with external consultants or partner with AI and data management experts to bridge skill gaps.
Why is AI-Ready Data Important?
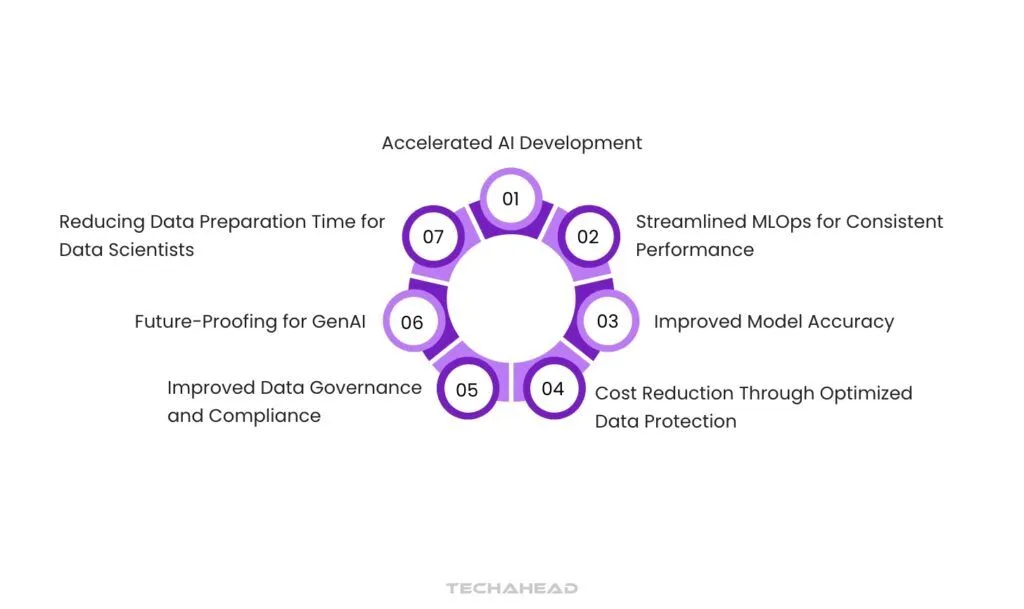 Accelerated AI Development
Accelerated AI Development
AI-ready data minimizes the time data scientists spend on data cleaning and preparation, shifting their focus to building and optimizing models. Traditional data preparation can be tedious and time-consuming, especially when data is unstructured or lacks consistency. With AI-ready data, data is pre-cleaned, labeled, and structured, allowing data scientists to jump straight into analysis. This efficiency translates into a quicker time-to-market, helping organizations keep pace in a rapidly evolving AI landscape where every minute counts.
Improved Model Accuracy
The accuracy of AI models hinges on the quality of the data they consume. AI-ready data is not just clean; it’s relevant, complete, and up-to-date. This enhances model precision, as high-quality data reduces biases and errors. For instance, if a retail company has AI-ready data on customer preferences, its models will generate more accurate recommendations, leading to higher customer satisfaction and loyalty. In essence, AI-ready data helps unlock better predictive accuracy, ensuring that organizations make smarter, data-driven decisions.
Streamlined MLOps for Consistent Performance
Machine Learning Operations (MLOps) ensure that AI models perform consistently from development to deployment. AI-ready data plays a vital role here by ensuring that both historical data (used for training) and real-time data (used in production) are aligned and in sync. This consistency supports smoother transitions between training and deployment phases, reducing model degradation over time. Streamlined MLOps mean fewer interruptions in production environments, helping organizations implement AI faster, and ensuring that models remain robust and reliable in the long term.
Cost Reduction Through Optimized Data Protection
AI projects can be costly, especially when data preparation takes a significant portion of a project’s budget. AI-ready data cuts down the need for extensive manual preparation, enabling engineers to invest time in high-value tasks. This shift not only reduces labor costs but also shortens project timelines, which is particularly advantageous in competitive industries where time-to-market can impact profitability. In essence, the more AI-ready a dataset, the less costly the AI project becomes, allowing for more scalable AI implementations.
Improved Data Governance and Compliance
In a regulatory environment, data governance is paramount, especially as AI decisions become more scrutinized. AI-ready data comes embedded with metadata and lineage information, ensuring that data’s origin, transformations, and usage are documented. This audit trail is crucial when explaining AI-driven decisions to stakeholders, including customers and regulators. Proper governance and transparency are not just compliance necessities—they build trust and enhance accountability, positioning the organization as a responsible AI user.
Future-Proofing for GenAI
With the rapid advancement in generative AI (GenAI), organizations need to prepare now to capitalize on future AI applications. Forward-thinking companies are already developing GenAI-ready data capabilities, setting the groundwork for rapid adoption of new AI technologies.
AI-ready data ensures that, as the AI landscape evolves, the organization’s data is compatible with new AI models, reducing rework and accelerating adoption timelines. This preparation creates a foundation for scalability and adaptability, enabling companies to lead rather than follow in AI evolution.
Reducing Data Preparation Time for Data Scientists
It’s estimated that data scientists spend around 39% of their time preparing data, a staggering amount given their specialized skill sets. By investing in AI-ready data, companies can drastically reduce this figure, allowing data scientists to dedicate more energy to model building and optimization. When data is already clean, organized, and ready to use, data scientists can direct their expertise toward advancing AI’s strategic goals, accelerating innovation, and increasing overall productivity.
Conclusion
In the data-driven landscape, preparing AI-ready data is essential for any organization aiming to leverage artificial intelligence effectively. AI-ready data is not just about volume; it’s about curating data that is accurate, well-structured, secure, and highly relevant to specific business objectives. High-quality data enhances the predictive accuracy of AI models, ensuring reliable insights that inform strategic decisions. By investing in robust data preparation processes, organizations can overcome common AI challenges like biases, errors, and data silos, which often lead to failed AI projects.
Moreover, AI-ready data minimizes the time data scientists spend on tedious data preparation, enabling them to focus on building and refining models that drive innovation. For businesses, this means faster time-to-market, reduced operational costs, and improved adaptability to market changes. Effective data governance and security measures embedded within AI-ready data also foster trust, allowing organizations to meet regulatory standards and protect sensitive information.
As AI technology continues to advance, having a foundation of AI-ready data is crucial for scalability and flexibility. This preparation not only ensures that current AI applications perform optimally but also positions the organization to quickly adopt emerging AI innovations, such as generative AI, without extensive rework. In short, prioritizing AI-ready data today builds resilience and agility, paving the way for sustained growth and a competitive edge in the future.
Source URL: https://www.techaheadcorp.com/blog/what-is-ai-ready-data-how-to-get-your-there/
We do not claim ownership of any content, links or images featured on this post unless explicitly stated. If you believe any content or images infringes on your copyright, please contact us immediately for removal ([email protected]). Please note that content published under our account may be sponsored or contributed by guest authors. We assume no responsibility for the accuracy or originality of such content. We hold no responsibilty of content and images published as ours is a publishers platform. Mail us for any query and we will remove that content/image immediately.
Copyright © 2024 IndiBlogHub.com. Hosted on Digital Ocean